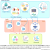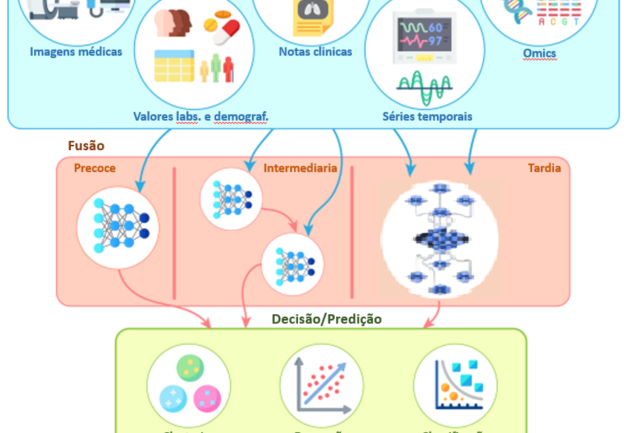
Temos visto cada vez mais o crescimento de linguagens generativas nas mais diversas atividades, sejam elas humanas ou não. Hoje a maioria dos modelos se baseiam em LLM (Large Language Model) para gerar os modelos generativos.
Quando começou a se tornar popular as IA generativas a primeira duvida que me surgiu foi de como essas linguagens aarmazenávam os dados.
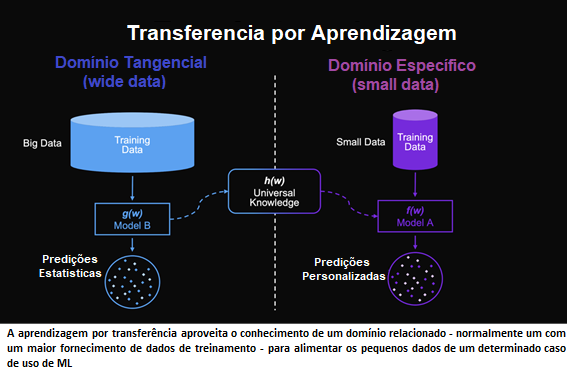
Wide Data e Small Data são termos que ganharam destaque, na última conferência da Gartner (EMEA) realizada entre os dias 18 e 20 de maio de 2021. Nesta conferencia a Gartner previu que até 70% das empresas estariam migrando suas soluções baseadas em Big Data para soluções baseadas em Wide Data e Small Data.

A flexibilidade das escolhas na organização quanto ao armazenamento de dados e compactação no Hadoop HDFS facilita o processamento dos dados.

Com a popularização do Big Data e Analytics, o aumento da complexidade dos dados e da forma de se trabalhar com eles, tornou-se um desafio definir o perfil de um time de arquitetura de dados somente com as habilidades dos profissionais com skill de DBA, administradores de dados e programadores de SQL.

Invariavelmente, os bancos de dados noSQL são usados, por exemplo, para coletar dados de fluxo de dados de sites de alto volume, monitorar o comportamento de varejo online.

Uma das principais dúvidas na qual se deparam as organizações é qual técnologia (Relacional ou NoSQL) utilizar para armazenar dados para Big Data.

Neste artigo tenho por objetivo detalhar o escopo de atuação da área de BI dentro de TI e qual a estrutura mínima necessária para que esta área seja viável.

Originalmente, o termo Centros de competência de BI (BICC – Business Intelligence Competence Center) foi utilizado pelo instituto de pesquisa GARTNER.