Introdução
Wide Data e Small Data são termos que ganharam destaque, na última conferência da Gartner (EMEA) realizada entre os dias 18 e 20 de maio de 2021. Nesta conferencia a Gartner previu que até 70% das empresas estariam migrando suas soluções baseadas em Big Data para soluções baseadas em Wide Data e Small Data.
A Gartner fez essa afirmação baseada em eventos como por exemplo a COVID-19 que está fazendo com que dados históricos que refletem condições passadas se tornem rapidamente obsoletos.
Aliado a este fato, a volta para um novo normal onde a sociedade mudou sua forma de consumir, se locomover e morar tornam muito dos dados coletados e armazenados até agora imprecisos para mecanismos de aprendizado de máquina ou IA. Com isto, os algoritmos hoje irão necessitar de dados mais profundos e detalhados para poder cumprir seu objetivo.
Mas antes de tomar qualquer ação no sentido de mudar o foco da solução atual da empresa é importante que se faça uma análise quanto ao nível de maturidade na gestão de dados em que a empresa se encontra e somente depois disto fazer algum movimento no sentido indicado pelo Gartner.
Migrando para uma visão de dados Wide Data
Muitas empresas já construíram seus data lakers, ou fez algum tipo de virtualização dos dados ou encontrou ainda uma forma própria de ver e analisar seus dados de forma integrada. Para as empresas que se enquadram em algum destes contextos chegou a hora de começar a pensar na evolução deste ambiente.
Agora o objetivo é integrar todas as informações sobre os dados da empresa e mantê-las de maneira uniforme em um dicionário corporativo.
As principais diferenças em relação aos modelos de dados ou dicionários de dados anteriores são a incorporação agora da singularidade específica que possui cada empresa e a incorporação do “ponto único da verdade” no contexto das definições e correlações de dados. A visão consistente dos dados em toda a empresa, permitirá que os repositórios de dados individuais de uma empresa sejam interconectados.
O desenvolvimento simultâneo de tópicos específicos de modelos de dados para qualquer novo sistema ou projeto ainda é possível dentro de uma arquitetura wide data. A condição para isto é que o desenvolvimento dos modelos seja baseado no dicionário corporativo.
Essa é a única maneira de garantir que as descrições e estruturas especializadas dos dados sejam válidas em toda a empresa tornando possível neutralizar a criação de silos de dados. Para estruturas e modelos de dados que cresceram historicamente (mais conhecido como legado), o desafio é garantir um mapeamento lógico com o dicionário corporativo.
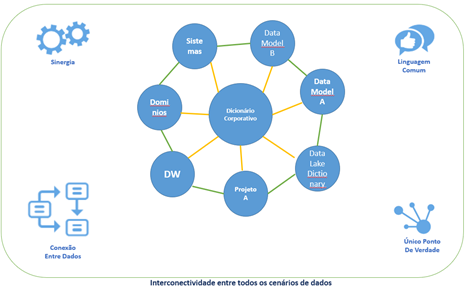
Com o dicionário corporativo, as empresas estão agindo de forma orientada para o futuro e avançando na integração e harmonização de dados dentro da própria organização e gerando valor agregado para:
- Compreensão uniforme de todos os dados entre as áreas funcionais relevantes e eliminação de arquiteturas de silo
- Ponto central de referência para o uso de termos técnicos; em caso de ambiguidades, a definição do dicionário corporativo se aplica a todos os departamentos
- Base para novas tecnologias de coleta e análise de dados
- Maior poder inovador e uma resposta mais rápida para o mercado
- Base de uma organização de BI moderna
Empresas que conseguirem alcançar o nível de maturidade de seus dados podem começar a aplicar análises X, com X significando encontrar links entre fontes de dados, independente do formato que estes dados estejam armazenados.
Small Data a partir de Wide Data
Por outro lado, em alguns casos não precisamos de aprendizado profundo de maquina para criar IA de alto desempenho.
Embora haja uma tendência de treinar IA usando o máximo de dados possível, em muitos casos os problemas não podem ser resolvidos apenas com big data. Algumas conclusões importantes só podem ser tiradas de pequenos dados.
Por exemplo, podemos obter uma visão precisa da personalidade, hábitos e motivações de um indivíduo apenas com pequenos dados. Pequenos dados podem ser empacotados com significados derivado dos dados pessoais exclusivos daquele indivíduo.
A IA deve ser capaz de extrair esse significado. Grandes conjuntos de dados obscurecem esse significado e os métodos de aprendizado de máquina normalmente aplicados a esses conjuntos de dados simplesmente calculam a média dessas informações. Agora o desafio é criar abordagens de IA que sejam capazes de encontrar valor em pequenos dados.
Com big data pode-se filtrar o ruído. Com pequenos dados tudo é significativo. Pequenos dados podem ser empacotados com significados derivados dos dados pessoais exclusivos daquele indivíduo. Pequenos dados podem ser analisados por humanos.
Além disso um único ser humano normalmente gera apenas pequenos dados. Portanto qualquer produto ou serviço otimizado para humanos em sua forma individual deve trabalhar com poucos dados. Quem quer ser tratado como uma pessoa comum ou um grupo de pessoas? Em última análise a IA precisa ser adaptada para uma pessoa e deve aprender com o feedback vindo exclusivamente dessa pessoa. Este é um pequeno trabalho de dados.
Quando fazemos análises baseadas em small data ocorre uma inversão de processos de machine learning. Em um processo de ML normalmente treinamos um modelo até que ele aprenda sobre os dados. Por outro lado, quando trabalhamos com small data o modelo já precisa saber extrair significado de um terminado conjunto de dados.
![]()
Conclusão
Uma linguagem de dados uniforme e integrada em um modelo de dados semântico é essencial para uma comunicação interdisciplinar eficiente para responder aos desafios atuais e futuros da empresa.
Um dicionário corporativo ajuda a entender seus próprios dados e usá-los como base para seu próprio desenvolvimento de longo prazo.
Em complemento, com um dicionário corporativo ativo, é possível extrair consistente porções de dados para criar modelos de IA. Estes pequenos conjuntos de dados podem vir inicialmente de um treinamento de big data.
No caso de IA baseado em small data o ideal é combinar a experiência humana e o treinamento por máquina de forma simultânea para inserir conhecimento de dados nos modelos de ML.











