
Introdução
Diante da rapidez das mudanças que ocorrem hoje devido a rápida digitalização da sociedade, as empresas, para não se tornarem obsoletas, sentem a necessidade de se modernizar e por conseguinte, modernizar os seus processos, principalmente os de TI. Dentre os vários termos novos surgidos um que vem chamando a atenção das empresas é o termo Big Data e dentro deste termo o Armazenamento poliglota.
A rapidez nas mudanças que o negócio necessita, muitas vezes esbarram na estrutura pesada de processos, aplicações e bases de dados que foram sendo construídas ao longo do tempo. Com o surgimento, crescimento e posterior popularização do Big Data, surgiram os meios para que se viabilize uma revolução na forma como se desenvolve e integram sistemas. Um dos frutos desta revolução é o DevOps.
DevOps surgiu para responder à necessidade que a infraestrutura e operações (IO) de TI tem de se juntar ao movimento Ágil, para entregar valor comercial mais rapidamente, melhorando a experiência do cliente. Esta abordagem transformou a forma como os times de IO passam a oferecer serviços e gerenciar mudanças.
Aliado a isto, a programação stateless baseada em containers e micro serviços está crescendo porque segmentos de código precisam ser executados em paralelo sem dependência de outro segmento de código. Pelo fato de o código poder ser executado sem dependência, torna-se mais fácil atualizar o código sem afetar outras partes do sistema.
Com isto, tem-se o aumento de implementações de banco de dados feitas em noSQL para responder a agilidade e rapidez que as organizações necessitam. Com banco de dados noSQL é possível atender as implementações de uma forma mais simples e rápida, custos mais baixos e “esquemas” adaptáveis em tempo real.
Diante deste cenário, iremos fazer um exercício de como seria uma arquitetura de dados onde os sistemas legados conviveriam com as novas tecnologias noSQL que estão surgindo.
Entendendo o problema da normalização
Ao trabalhar com bancos de dados relacionais, aprendemos que devemos normalizar até não ser possível normalizar mais nada.
Normalizar os dados normalmente envolve termos uma entidade, como por exemplo pessoa, e dividi-la em dados discretos. Nos casos mais comuns, uma pessoa pode ter vários registros de detalhes de contato, bem como vários registros de endereços. Pode-se avançar um pouco mais e dividir os detalhes de contato extraindo mais campos comuns como um tipo. O mesmo para o endereço, cada registro aqui tem um tipo como Residencial ou Profissional. Ainda especializamos a pessoa em cliente, funcionário e prospect (pessoa que fez um primeiro contato através do call center e não se transformou efetivamente em um cliente).
A premissa de orientação ao normalizar dados é evitar o armazenamento de dados redundantes em cada registro. No exemplo de pessoa, com todos os seus detalhes de contato e endereços, é necessário usar JOINS para efetivamente agregar os dados em tempo de execução.
A armadilha neste modelo está no fato que qualquer consulta ou atualização de uma pessoa com seus detalhes de contato, endereços, etc requer operações de gravação e consulta em muitas tabelas individuais.
Outro problema também encontrado é que pelo fato das tabelas possuírem relacionamento físico, uma mudança na regra de negócio que venha a alterar ou ferir este relacionamento causa grande impacto em modelo (base de dados) e aplicações.
O problema de quebra de modelo contribui para o fato de ser difícil desenvolver aplicações usando metodologias ágeis e automatizar o processo de deploy em bases legadas.
noSQL ou Relacional?
Invariavelmente, os bancos de dados noSQL são usados, por exemplo, para coletar dados de fluxo de dados de sites de alto volume, monitorar o comportamento de varejo online, agregar dados de sensores em tempo real e suportar comunicações de redes sociais. Atualmente eles veem sendo usados para dados transacionais e em uma gama variada de aplicações.
A maioria dos sistemas de gerenciamento de banco de dados relacionais aderem ao padrão ACID – atomicidade, consistência, isolamento e durabilidade – para garantir que os dados estejam sempre em um estado previsível e protegido. Os bancos de dados noSQL adotam uma abordagem diferente no armazenamento de dados aderindo ao padrão BASE descrito aqui:
- Basically Available: os dados são replicados e particionados em vários nós para garantir que ele esteja disponível mesmo em caso de falhas múltiplas.
- Soft state: ao contrário dos sistemas baseados em ACID que buscam consistência, um banco de dados noSQL permite que os dados estejam em um estado inconsistente. Isso pode ocorrer depois que os dados são modificados, mas não totalmente replicados.
- Eventual consistency: depois de ter sido completamente replicado, os dados são levados a um estado consistente.
Embora um banco de dados noSQL possa suportar grandes conjuntos de dados e operações de baixa latência, ele não fornece o tipo de controle granular que um banco de dados relacional faz para garantir a integridade dos dados e reduzir a redundância de dados e inconsistências. Por outro lado, devido ao fato de não estar amarrado as regras de normalização e relacionamento dos bancos relacionais, bancos noSQL fornecem flexibilidade e agilidade que o negócio hoje demanda.
Pelas características dos bancos noSQL, estes se encaixam como uma luva nas propostas de desenvolvimento ágil e entrega continua presentes na proposta de DevOps.
Por que não ambos (noSQL e Relacional)?
Um sistema corporativo complexo usa diferentes tipos de dados e geralmente integra informações de diferentes fontes. As aplicações que hoje estão sendo construídas usando tecnologias como micro serviços ou equivalentes tendem a gerenciar sua própria coleção de dados. A forma como este componente manipula o dado ou o requisito que ele está atendendo definirá qual o melhor tipo de armazenamento de dados. Estamos de fato chegando a era da persistência de dados poliglota onde o que definirá o seu repositório de dados é o requisito que o componente que está sendo construído irá atender.
Sair do mundo relacional onde se possui forçosamente uma certa governança de dados para um tipo de desenvolvimento onde conjuntos de dados noSQL são criados de acordo com a necessidade da aplicação é um desafio.
Empresas com mais tempo no mercado já possuem uma certa maturidade dos seus dados. Maturidade neste contexto significa a empresa saber dentro do seu universo de dados relacional quais dados chaves são ou estão maduros e que não sofrerá nenhum tipo de mutação ao longo do tempo. Como exemplo temos por exemplo o código de um cliente ou código de um produto. Seja o dado guardado em uma base relacional ou não, um produto ou um cliente sempre deverá ter um identificador único dentro da organização.
Por outro lado, os negócios evoluem e neste processo de evolução novos requisitos que acabam se transformando em estruturas de dados tem que ser atendidos pelos sistemas. Posso citar por exemplo, no caso de pacientes, onde hoje não é guardado o seu sequenciamento genético, mas por uma questão de negócio é preciso passar a guarda-lo junto com as informações de cliente.
Tentando conciliar a maturidade de dados que as empresas já possuem e as novas tecnologias noSQL existentes, proponho a criação de um tipo de arquitetura de dados que chamo de relational thin.
Não foi encontrado este termo ainda em nenhuma literatura, então vou tentar nas próximas linhas explicar como visualizo esta arquitetura.
Relational Thin
Existem normalmente nos sistemas legados milhares de tabelas, muitas com dados que já não possuem mais sentido de existir, dados replicados, dados desnormalizados ou sem relacionamento que foram criados para não quebrar a estrutura das aplicações existente, etc.
Por que não fatorar estas tabelas, extraindo delas os dados que são a base do negócio e formar uma rede de dados relacionais leve, só com os dados essenciais e construir uma malha de dados relacional onde se tenha ACID, constraint e toda a segurança que um banco de dados relacional oferece.
Dentro desta malha de dados relacional desenvolve-se os dados não relacionais que irão atender as necessidades do negócio e sustentar sua evolução.
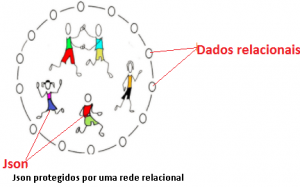
Talvez com um exemplo as coisas fiquem mais claras.
Temos hoje o nosso conceito de pedido e item que é dentro das organizações uma estrutura universal. Ela apenas muda de nome (ficha/item, ov/item ov, etc) e assim por diante.
Todo o item lançado na ficha tem que estar obrigatoriamente relacionado a um pedido. Isto é um requisito forte de negócio e tem que ter por isto uma consistência forte. Em compensação, outras informações de pedido/item surgiram com a evolução do negócio como por exemplo taxas, insumos, conjunto de peças ou exames ou produtos e assim por diante.
É necessário ter uma consistência forte entre pedido e item porque ele é a base de nossa ficha, mas todas as outras informações, embora importante, não são a base, mas sim componentes.
Poderíamos ter um modelo relacional somente com as informações importantes de pedido/item e o restante deixaríamos em um json (se este for o formato escolhida) dentro de um banco noSQL orientado a documento que teriam seu relacionamento garantido através dos IDs da base relacional.
Vale lembrar que nos bancos não relacionais orientados a documento a forma de se relacionar duas colection é através dos IDs de cada colection replicados em uma relação 1:M, M:1 ou M:M onde, no caso de M:M deverá surgir uma 3a. Colection para guardar o ID das outras duas. Estas recomendações podem ser vistas nas documentações de modelagem do mongoDB e cosmosDB da Azure. O ponto aqui é que o responsável exclusivo por manter a integridade deste relacionamento é a aplicação e não o banco de dados.
Continuando nosso exemplo, para a estrutura de pedido/item teríamos, de forma simplificada, um modelo de dados relacional essencial com mais ou menos esta aparência:
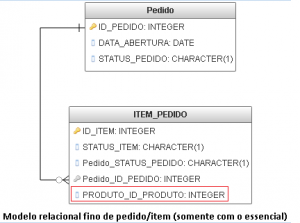
Complementado por uma estrutura json similar a esta.

Note que:
- Os IDs do relacional estão presentes no arquivo JSON, garantindo que haja uma certa integridade de dados
- A estrutura JSON acima comporta todos os elementos do pedido (item, insumos, taxas)
- Esta estrutura suporta amplamente novos requisitos de negócio, como por exemplo subconjunto de um item.
- O ID de produto destacado no modelo relacional não possui relacionamento físico pois o mesmo iria gerar um acoplamento entre “silos” de negócio (produto e pedido) prejudicando ou impedindo que pudesse ser implementado DevOps.
Este tipo de abordagem tem, na minha visão, três vantagens:
A primeira é o fato de termos um banco de dados relacional extremamente leve, o que possibilita colocar ele na nuvem, em um banco de custo baixo (mysql ou postgree por exemplo) ou se preferir deixar ele in memory. Com um banco relacional in memory, teríamos um ganho de performance segundo os benchmarks disponíveis da ordem de 90%.
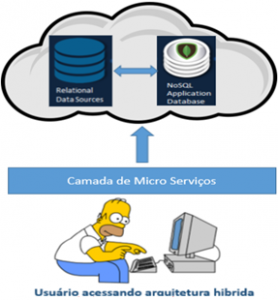
A segunda é a possibilidade de tornar mais simples a integração dos dados híbridos (relacional + JSON) com o BI existente na empresa, uma vez que teríamos garantido uma estrutura mínima de agregação baseada no relacional, sendo os documentos gravados em JSONs complementos para esta estrutura.
A terceira é a facilidade de tornar a convivência ou a transição entre legado e uma nova arquitetura de dados mais leve e uma vez que para construir uma camada de integração entre a estrutura antiga com a nova estrutura baseada no relacional+json uma vez que os principais IDs em ambas as estruturas se relacionam.
Considerações Finais
Cada tecnologia de dados tem seus prós e contras. Tirar o melhor proveito de cada uma delas é o principal desafio hoje das empresas. Cada vez mais o requisito da aplicação vai orientar os desenvolvedores sobre a escolha da melhor tecnologia.
Com todas essas novas formas de se guardar dados, a governança de dados passa a ser um desafio. Ela vai precisar unir a visão já existente das bases de dados relacionais ou multidimensionais com as novas bases noSQL que surgem definindo desta maneira a forma de integração das bases noSQL com os sistemas de tomada de decisão da empresa.








2 comentários
Excelente artigo, claro e bem objetivo! Interessante o termo Relational Thin, extrair o melhor de cada mundo (Relacional X NoSQL) é um grande desafio e inovação.
Parabéns pelo artigo, muito interessante!