
Introdução
Embora a flexibilidade das escolhas na organização quanto ao armazenamento de dados e compactação no Hadoop HDFS facilite o processamento dos dados, a compreensão das escolhas quanto a forma de armazenamento e o seu impacto na pesquisa, no desempenho e na usabilidade permite se pensar e melhores padrões de design quanto a arquitetura de armazenamento destes dados.
O HDFS é usado muito comumente para fins de armazenamento de dados, mas existem também outros sistemas comumente usados, como o HBase por exemplo, que apesar de armazenar os dados no HDFS possui uma forma própria de gerenciamento dos dados. Todos os formatos de armazenamento devem ser consideradas no desenho de uma arquitetura Hadoop. Há vários formatos de armazenamento e compactação adequados para diferentes casos de uso. Para armazenar dados brutos pode haver um certo formato de armazenamento e, após o processamento, pode se guardar os dados em outro formato de armazenamento diferente. Isso depende do padrão de acesso.
Principais considerações para o armazenamento de dados
Formato de arquivo
Existem vários formatos de armazenamento que são adequados para armazenar dados no HDFS, como arquivos de texto simples, formatos de arquivo avançados como Avro e Parquet, formatos específicos do Hadoop como sequence files. Esses formatos têm seus próprios prós e contras dependendo do caso de uso.
Compressão
As soluções de Big Data devem ser capazes de processar uma grande quantidade de dados em tempo rápido. A compactação de dados acelera as operações de I / O e economiza espaço de armazenamento. Mas isso pode aumentar o tempo de processamento e a utilização da CPU devido à descompactação. Portanto, o equilíbrio é necessário – quanto maior a compactação – menor é o tamanho dos dados, mas em contrapartida é maior o processamento e a utilização da CPU.
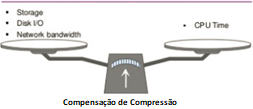
Os arquivos compactados também devem ser divisíveis para suportar o processamento paralelo. Se um arquivo não é divisível, isso significa que não podemos inseri-lo em várias tarefas em paralelo e, portanto, perdemos a maior vantagem de estruturas de processamento paralelo do Hadoop, Spark etc.
Armazenamento de dados com base no padrão de acesso
Em qualquer sistema Hadoop os dados residem no HDFS, mas os pontos de decisão precisam ser considerados tais como se o acesso aleatório de dados é necessário e também se atualizações frequentes são necessárias. Os dados no HDFS são imutáveis, por isso, para atualizações frequentes precisamos de armazenamento semelhante ao do HBase que suporta atualizações.
Organização de dados
Abaixo estão os princípios e considerações para organizar os dados na camada de armazenamento do Hadoop:
- A estrutura da pasta deve ser auto descritiva para descrever quais dados ela contém
- A estrutura de pastas também deve estar alinhada com vários estágios de processamento, isto é, se houver vários estágios de processamento. Isso é necessário para executar novamente o lote de qualquer estágio se algum problema ocorrer durante o processamento.
- A estratégia de particionamento também descreve qual deve ser a estrutura do diretório.
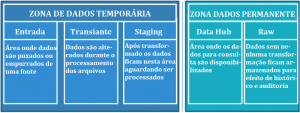
Exemplo de uma estrutura típica de pastas autoexplicativas que possui diferentes zonas de dados:
Formatos comuns de arquivos
Como já discutimos na seção acima, os dados da camada de armazenamento do Hadoop são divididos em vários estágios. Para simplificar a discussão vamos classificar os dados armazenados em duas categorias simples:
- Dados brutos (Raw Data)
- Dados processados
Para dados brutos, os padrões de acesso seriam diferentes dos dados processados e, portanto, os formatos de arquivo seriam diferentes dos dados processados. Para fazer processamento sobre dados brutos geralmente usamos todos os campos de dados e, portanto, nosso sistema de armazenamento subjacente deve suportar esse tipo de uso de forma eficiente, mas só acessaremos apenas algumas colunas de dados processados em nossas consultas analíticas por isto nosso sistema de armazenamento subjacente deve ser capaz de lidar com esse caso de maneira mais eficiente em termos de I / O de disco etc.
Arquivo de texto simples
Um caso de uso muito comum do ecossistema Hadoop é o de armazenar arquivos de log ou outros arquivos de texto simples com dados não estruturados para fins de armazenamento e análise. Esses arquivos de texto podem facilmente ocupar todo o espaço em disco, portanto, é necessário um mecanismo de compactação adequado dependendo do caso de uso. Por exemplo, algumas organizações usam o HDFS apenas para armazenar dados arquivados. Nesse caso, a utilização da melhor compactação é necessária, pois dificilmente haveria qualquer processamento nesses dados. Por outro lado, se os dados armazenados forem usados para fins de processamento, um formato de arquivo divisível om um nível de compactação aceitável é necessário.
Também devemos considerar o fato de que quando os dados são armazenados como arquivos de texto haverá sobrecarga adicional de conversões de tipo. Por exemplo, armazenar 10000 números inteiros como string ocuparia mais espaço e também exigiria conversão de tipo de string para Integer no momento da leitura. Essa sobrecarga aumenta consideravelmente quando temos o processamento de TBs de dados.
Dados de texto estruturados
Existem formas mais sofisticadas de arquivos de texto com dados em alguns formulários padronizados, como arquivos CSV, TSV, XML ou JSON. No Hadoop, não há um formato de entrada construído para manipular arquivos XML ou JSON. Por não haver tags de início ou finalização em JSON há uma dificuldade em trabalhar com arquivos JSON pois é difícil dividir esses tipos de arquivos.
Arquivos binários
Para a maioria dos casos o armazenamento de arquivos binários, como imagens / vídeos, etc. no formato Container como sequence files é preferido, mas para arquivos binários muito grandes é preferível armazenar os arquivos como estão.
Formatos de arquivo específicos para big data
Existem muitos formatos de arquivo específicos para big data como estruturas de dados baseadas em arquivos como por exemplo sequence files, formatos de serialização como Avro, formatos colunares como Parquet ou ORC.
Arquivos sequenciais
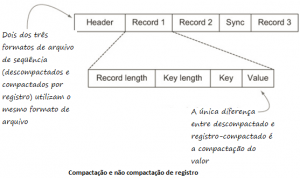
Esses arquivos contêm dados como pares binários de chave-valor. Existem mais 3 formatos que são:
- Descompactado – sem compactação
- Registro compactado – Os registros são compactados quando são adicionados ao arquivo.
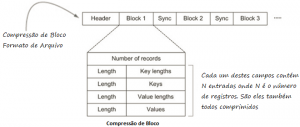
- Bloco compactado – Este formato aguarda até que os dados cheguem ao tamanho do bloco para depois serem compactados.
Bloco compactado fornece melhor compactação do que apenas registro compactado. Um bloco se refere a um grupo de registros compactados juntos dentro de um bloco HDFS. Pode haver vários blocos de arquivos sequenciais dentro de um bloco HDFS.
Uso, Vantagens e Desvantagens
- Estes são usados principalmente como contêiner para arquivos pequenos. Como o armazenamento de muitos arquivos pequenos no HDFS pode causar problemas de memória no NameNode, o número de tarefas criadas durante o processamento pode causar sobrecarga extra.
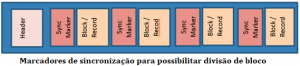
- Arquivos sequenciais contém marcador de sincronização para distinguir entre vários blocos que o torna divisível. Então agora você pode obter divisibilidade com formato de compactação não divisível em tabela como não tratável. Você pode compactar os blocos individuais e manter a natureza divisível usando marcadores de sincronização.
- As desvantagens do arquivo sequencial são que elas não são neutras em relação à linguagem e só podem ser usadas com aplicativos baseados em Java.
Avro
- Avro é uma linguagem neutra para serialização de dados.
- Tabelas escritas tem a desvantagem de que elas não fornecem portabilidade de idioma.
- Dados formatados em Avro podem ser descritos através de esquema independente de linguagem, portanto, os dados formatados pelo Avro podem ser compartilhados entre aplicativos usando idiomas diferentes.
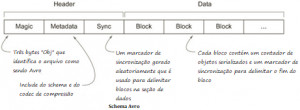
- Avro armazena o esquema no cabeçalho do arquivo para que os dados sejam auto-descritivos.
- Os arquivos formatados pelo Avro são divisíveis e compactáveis e, portanto, são bons candidatos para armazenamento de dados no ecossistema Hadoop.
- Evolução de schema – Esquema usado para ler um arquivo Avro não precisa ser o mesmo esquema que foi usado para gravar os arquivos. Isso possibilita adicionar
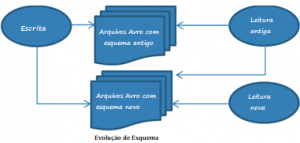
- O Schema Avro geralmente é escrito no formato JSON. Também podemos gerar arquivos de esquema usando utilitários fornecidos pela Avro a partir de POJOs Java.
- Classes Java correspondentes também podem ser geradas a partir do schema do arquivo Avro.
- Assim como com os sequence files, os arquivos Avro também contêm marcadores de sincronização para separar os blocos. Isso os torna divisível.
- Esses blocos podem ser compactados usando formatos de compactação como Snappy e Deflate.
- O Hive fornece o SerDe embutido (AvroSerDe) para ler e gravar dados na tabela.
- Tipos de dados suportados – integer, boolean, float, string, double, map, tipos de dados complexos de matriz, tipos de dados aninhados etc.
Formatos Colunares
Formatos colunares são geralmente usados onde você precisa consultar algumas colunas em vez de todos os campos em linha, porque o padrão de armazenamento orientado por coluna é adequado para o mesmo. Por outro lado, os formatos de linha são usados onde você precisa acessar todos os campos da linha. Então, geralmente, o Avro é usado para armazenar os dados brutos, porque durante o processamento, geralmente, todos os campos são necessários.
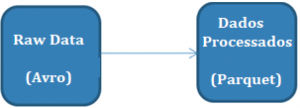
As principais vantagens do formato colunar são:
- Eles eliminam I / O para colunas que não fazem parte da consulta, portanto, funciona bem para consultas que exigem apenas subconjunto de colunas.
- Fornece melhor compactação pois dados semelhantes são agrupados em formato colunar.
Parquet
- Funcionam bem onde apenas poucas colunas são necessárias na consulta / análise.
- Apenas as colunas necessárias serão buscadas / lidas, reduzindo o I / O do disco.
- Adequado para tipos de soluções de data warehouse em que as agregações são necessárias em determinada coluna ou em um conjunto enorme de dados.
Predicado Pushdown / Filtro Pushdown
Conceito que é usado no momento da leitura de dados de qualquer armazenamento de dados. Ele é seguido pela maioria dos RDBMS e agora foi seguido por formatos de armazenamento de dados grandes como Parquet e ORC também.
Quando usamos alguns critérios de filtragem, o armazenamento de dados tenta filtrar os registros no momento da leitura do disco. Esse conceito é chamado de pushdown de predicado. A vantagem do pushdown de predicado é que menos I / O de discos acontecerão e, portanto, o desempenho sera melhor. Caso contrário, dados inteiros serão trazidos para a memória e em seguida, filtrados, o que resulta em um grande requisito de memória.
Pushdown de Projeção
Quando os dados são lidos do armazenamento de dados, apenas as colunas necessárias serão lidas. Geralmente os formatos colunares como Parquets e ORC seguem esse conceito, o que resulta em melhor desempenho de I / O.
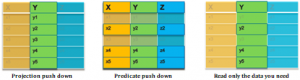
Modelo de objeto, conversores de modelo de objeto e formato de armazenamento
- O modelo de objeto está na representação de memória dos dados. No Parquet é possível alterar o modelo de objeto para Avro, o que fornece um modelo de objeto rico.
- Formato de armazenamento é a representação serializada de dados no disco. Parquet tem formato colunar.
- Os conversores de Modelo de Objetos são responsáveis por converter os dados para o tipo de dados do Parquet e vice-versa em tipos de dados do Modelo de Objeto.
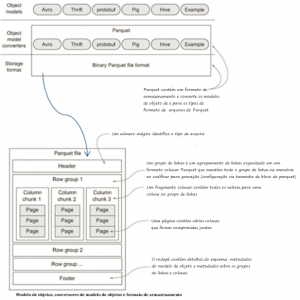
Hierarquicamente, um arquivo consiste em um ou mais grupo de linhas. Um grupo de linhas contém exatamente um bloco de coluna por coluna. Pedaços de colunas contêm uma ou mais páginas.
Configurabilidade e otimizações
- Tamanho do grupo de linhas: grupos de linhas maiores permitem blocos de colunas maiores o que possibilita a realização de IOs sequenciais maiores. Grupos maiores também exigem mais buffer no caminho de gravação (ou uma gravação de duas passagens). Recomenda-se grandes grupos de linhas (512MB – 1GB). Como um grupo de linhas inteiro pode precisar ser lido, o que se deseja é que ele se encaixe completamente em um bloco HDFS. Portanto, o tamanho do bloco HDFS também deve ser configurado para ser maior. Uma configuração de leitura otimizada seria: grupos de linhas de 1 GB, tamanho de bloco de 1 GB HDFS e 1 bloco de HDFS por arquivo HDFS.
- Tamanho da página de dados: as páginas de dados devem ser consideradas de forma individual de modo que as páginas de dados menores permitam uma leitura mais detalhada (por exemplo, pesquisa de linha única). Tamanhos de página maiores incorrem em menos sobrecarga de espaço (menos cabeçalhos de página) e potencialmente menos análise de custos indiretos (cabeçalhos de processamento). Nota: para varreduras sequenciais não é esperado que se leia uma página por vez. Recomenda-se 8 KB para tamanhos de página.
ORC
- Formato colunar
- Tabela dividida
- Armazena dados como grupo de linhas e cada grupo tem armazenamento colunar.
- Permite indexação dentro de um grupo de linhas.
- Não é um formato de propósito geral, pois foi projetado para executar com o Hive. Não podemos integrá-lo a mecanismo de consulta como o Impala.
Desenho de Esquema
Embora o armazenamento de dados no Hadoop seja um esquema menos natural, ainda há muitos outros aspectos que precisam ser tratados. Isso inclui a estrutura de diretórios no HDFS, bem como a saída do processamento de dados.
Particionamento
É uma maneira comum de reduzir o I / O de disco durante a leitura do HDFS. Normalmente os dados no HDFS são muito grandes e a leitura de todo o conjunto de dados não é possível e também não é necessária em muitos casos. Uma boa solução é dividir os dados em partes / partições e ler o pedaço necessário. Considerações sobre particionamento:
- Não particione em coluna, onde se pode acabar com muitas partições.
- Não particione em coluna onde se acaba com muitos arquivos pequenos nas partições.
- É bom ter tamanho de partição de ~ 1 GB.
Bucketing
Às vezes, se tentarmos particionar os dados em algum atributo para o qual a cardinalidade é alta o número de partições possíveis a ser criada pode exceder. Por exemplo, se tentarmos particionar os dados por um campo chamado tradeId, o número de partições criadas seria muito grande. Isso pode causar o problema “Excesso de arquivos pequenos”, resultando em problemas de memória no nameNode e também o processamento de tarefas criadas seria maior (igual ao número de arquivos) quando processado com o Apache Spark.
Em tais cenários, é recomendável criar partições / blocos hash. Uma vantagem adicional de bucketing é que ao unir dois conjuntos de dados como por exemplo dados de atributos de negociação (Deal number, Deal date etc.) com dados de atributos de risco de negociação (Risk measure type, risk amount) para fins de relatório é possível estabelecer esta relação com um campo tradeId por exemplo.
Desnormalização e pré-agregações
No Hadoop, é aconselhável armazenar os dados no formato Denormalized, de modo que haja menos requisitos para unir os dados. As junções são operações mais lentas no Hadoop, pois envolvem geralmente grande quantidade de dados.
Portanto, os dados devem ser pré-processados para desnormalização e pré-agregados, se forem necessárias agregações frequentes.
Achatado X aninhado
Tanto no Avro quanto no Parquet você pode ter dados estruturados planos, bem como dados de estrutura aninhada.
Referências
Hadoop in Practice, Second Edition
By: Alex Holmes
Publisher: Manning Publications
Pub. Date: September 29, 2014
Url: http://techbus.safaribooksonline.com/book/databases/hadoop/9781617292224
Data Lake Development with Big Data
By: Pradeep Pasupuleti; Beulah Salome Purra
Publisher: Packt Publishing
Pub. Date: November 26, 2015
Url: http://techbus.safaribooksonline.com/9781785888083
Hadoop Application Architectures
By: Mark Grover; Ted Malaska; Jonathan Seidman; Gwen Shapira
Publisher: O’Reilly Media, Inc.
Pub. Date: July 15, 2015
Url: http://techbus.safaribooksonline.com/book/databases/hadoop/9781491910313











