Quando começou a se tornar popular as IA generativas a primeira duvida que me surgiu foi de como essas linguagens aarmazenávam os dados. Por ser uma pessoa de dados me intrigava de como essas linguagens conseguiam gravar e acessar uma quantidade enorme de dados correlacionados. Foi aí que comecei a conhecer bancos de dados vetoriais, tecnologia que até então só tinha ouvido falar nos meios acadêmicos.
Vale ressaltar primeiro a diferença entre um indice de vetores e um banco de dados de vetores.
Um índice de vetores como por exemplo o FAISS (Facebook AI Similarity Search) podem melhorar significativamente a pesquisa e recuperação de incorporações de vetores, mas carecem de recursos que existem em qualquer banco de dados.
Por outro lado, um banco de dados vetorial faz uso de IA generativa para executar análises relacionadas à pesquisa de similaridade e detecção de anomalia, muitas vezes fazendo uso de dados temporais, ou seja, dados com carimbo de tempo que nos dizem não apenas ‘o que’ aconteceu, mas a sequencia em que estes fatos aconteceram em relação a todos os outros eventos em qualquer dado sistema de TI. Vetores são “objetos” de dados, ou seja, são valores numéricos que expressam espaço, lugar, tempo e várias outras características classificatórias que nos permitem colocar um valor granular e significado em nossos dados.
Por serem extremamente rápidos em termos de poder de computação (eles podem ingerir dados e também executar ações como replicação e fragmentação de dados particionados em alta velocidade), os vetores nos permitem construir armazenamentos de dados que ‘entendem’ os valores mantidos em diferentes formatos de dados.
Sabemos que metadados são “informação sobre a informação”, com isto, imagem, musica e vídeo possuem informações que ajudam a identificar do que se trata determinado arquivo.
Aplicando isto a vetores, se um processo de IA tiver que decidir se uma determinada imagem está mostrando um cachorro ou um gato, muito provavelmente, ao examinar apenas os dados básicos dessa imagem pode não ser suficiente; afinal, ambos os animais têm quatro patas, pelos, dentes afiados e são considerados animais domésticos. Se usarmos vetores para atribuir ‘atributos’ para a imagem, então podemos usar o poder de Large Modelos de linguagem (LLMs) com IA generativa para examinar outras características da imagem. Se a legenda da imagem indicar que o animal pode ser levado para um ‘passeio’, então podemos provavelmente inferir que é um cachorro. Isso ocorre porque os LLMs procuram sequências de palavras que são mais propensos a se complementarem. Embora 1 em cada 1.000 pessoas leve seu gato para passear na coleira, essa anomalia faz parte da lógica vetorial e não impede a máquina de decidir que a foto é de um cachorro.
Um vetor é como um mapa onde qualquer objeto (de uma perspectiva de dados) pode ser expresso em listas e tabelas baseadas em séries temporais e informações. Vivemos em um mundo onde a maioria das informações existentes não é estruturado (documentos de texto, feeds de mídia social, fluxo de bate-papo, imagens e arquivos de vídeo etc.), mas se atribuirmos vetores a essas informações podemos começar a gerenciá-las de novas maneiras. Os vetores nos permitem ir tão granular quanto precisamos para qualquer assunto e listar várias centenas de atributos para um objeto de dados escolhido. Bancos de dados vetoriais simplificam a codificação de muitas dimensões e informações de séries temporais sendo sempre a chave entre esses atributos e suas respectivas dimensões.
Voltando a indice de vetores, o principal desafio de trabalhar com estes vetores incorporados ao código é que os mesmos não conseguem acompanhar a complexidade e a escala dos dados, dificultando a extração de insights e a realização de análises em tempo real.
Com um banco de dados vetorial, podemos adicionar recursos avançados aos nossos AIs, como informações semânticas, recuperação, memória de longo prazo e muito mais. O diagrama abaixo nos dá uma melhor compreensão do papel dos bancos de dados vetoriais neste tipo de aplicação:
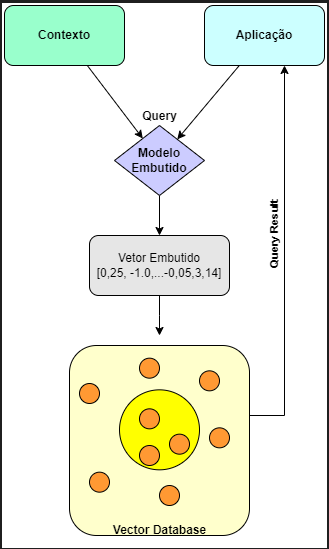
Vamos a uma breve explicação:
- Primeiro, usamos o modelo para criar um conjunto de vetores para o conteúdo que desejamos indexar.
- Esses vetores são inseridos no banco de dados junto com a referencia do conteúdo original que foi utilizada para criar o vetor.
- Posteriormente, quando o aplicativo faz uma consulta, usamos o mesmo modelo para criar um conjunto de vetores para a consulta O anco retornará os conjuntos de vetores semelhantes a consulta solicitada.
Dada esta pequena explicação, agora podemos ver como os algoritmos embutidos dentro do banco de dados de vetores podem em muito facilitar a vida. O objetivo é permitir consultas rápidas criando uma estrutura de dados que pode ser percorrida rapidamente. Eles irão comumente transformar a representação do vetor original em um formato compactado para otimizar a consulta.
- Projeção randomica
A ideia básica por trás da projeção randomica é projetar os vetores de alta dimensão para um espaço dimensional inferior usando uma matriz de projeção randominca. Criamos uma matriz de números aleatórios. O tamanho da matriz será o valor alvo de mais baixa dimensão que desejamos. Nós então calculamos o produto escalar dos vetores de entrada e a matriz, que resulta em uma matriz projetada que tem menos dimensões do que nossos vetores originais, mas ainda preserva sua similaridade.
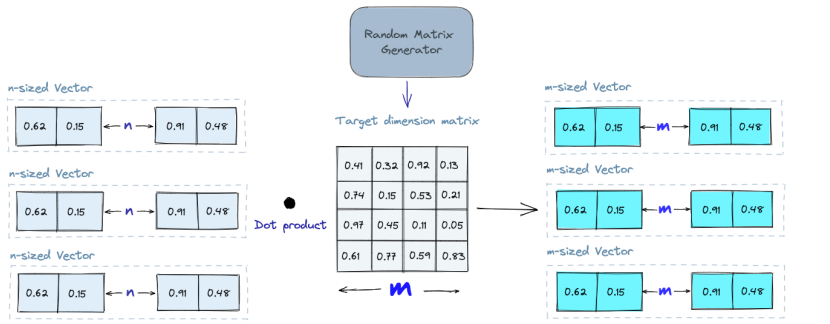
Quando consultamos, usamos o mesmo algoritmo de geração de matriz. Submetemos essa consulta ao banco para encontrar os vizinhos mais próximos. Como a dimensionalidade dos dados é reduzida, o processo de pesquisa é significativamente mais rápido do que pesquisar todas combinações de matriz possíveis. Lembre-se de que a projeção randomica é um método aproximado e a qualidade da consulta depende das propriedades da matriz que foi submetida ao banco.
- Quantização do produto
Outra maneira de construir um índice é a quantização do produto (PQ), que é uma compressão com perdas técnica para vetores de alta dimensão (como incorporações de vetores). Pega-se o vetor original, divide-o em pedaços menores, simplifica a representação de cada pedaço criando um “código” representativo para cada bloco e, em seguida, reúne todos os blocos novamente – sem perder informações vitais para as operações de similaridade. O processo de QP pode ser dividido em quatro etapas: divisão, treinamento, codificação e consulta.
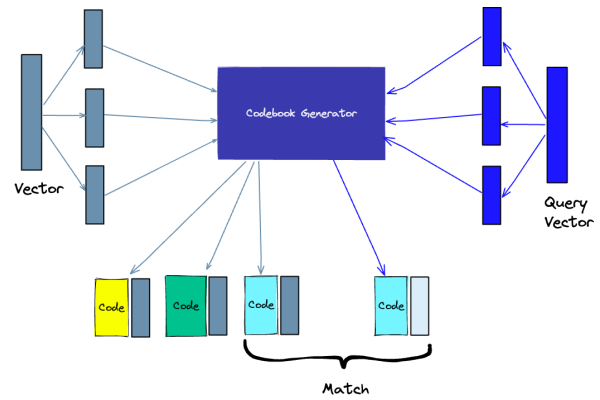
O número de vetores representativos no codebook é um trade-off entre a precisão da representação que está armazenada no banco e o custo computacional de pesquisar todo o codebook. Quanto mais vetores representativos armazenados no codebook, mais precisa será a representação dos vetores no banco, mas em contrapartida se pagará um maior custo computacional para pesquisar o este codebook. Em contraste, quanto menos vetores representativos no codebook, menos precisa a representação, mas com isto teremos um menor custo computacional.
- Hash sensível à localização
Hash sensível a localização (LSH) é uma técnica de indexação que atua no contexto de uma pesquisa do vizinho mais próximo. Ele é otimizado para velocidade fornecendo um resultado aproximado. O LSH mapeia vetores semelhantes em “buckets” usando um conjunto de funções de hash, como visto abaixo:
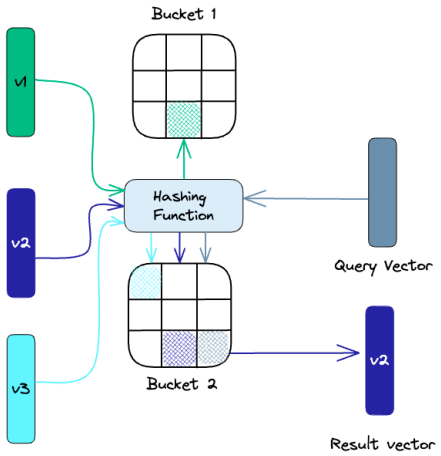
Para encontrar os vizinhos mais próximos para um determinado vetor de consulta, usamos as mesmas funções de hash usadas para gravar nos buckets. O vetor de consulta busca o hash específicado na consulta e em seguida, busca as correspondências mais próximas nos buckets. Esse método é muito mais rápido do que pesquisar em todo o conjunto de dados porque há muito menos vetores em cada tabela hash do que em todo o espaço.
É importante lembrar que o LSH é um método aproximado e a qualidade da aproximação depende das propriedades das funções hash. Em geral, quanto mais hash funções utilizadas, melhor será a qualidade da aproximação. No entanto, usando um grande número de funções de hash podem ser computacionalmente caras e podem não ser viáveis para grandes conjuntos de dados.
- Pequeno mundo hierarquico navegável (HNSW)
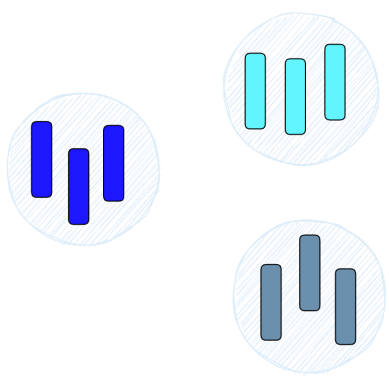
HNSW cria uma estrutura hierárquica semelhante a uma árvore, onde cada nó da árvore representa um conjunto de vetores. As arestas entre os nós representam a similaridade entre os vetores. O algoritmo começa criando um conjunto de nós, cada um com um pequeno número de vetores. Isto pode ser feito aleatoriamente ou agrupando os vetores com algoritmos como k-means, onde cada cluster torna-se um nó.
O algoritmo então examina os vetores de cada nó e desenha uma aresta entre os nós com maior semelhança entre si.
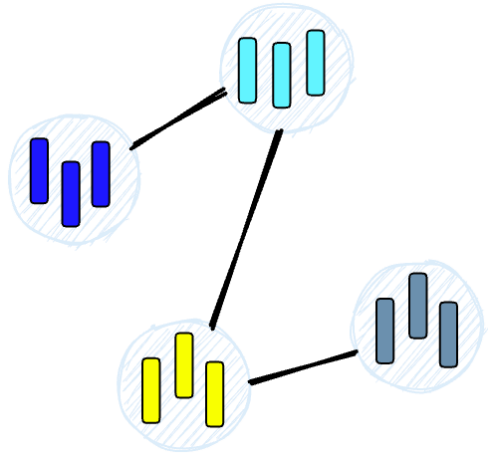
Quando consultamos um índice HNSW, ele usa este grafo para navegar pela árvore, visitando os nós com maior probabilidade de conter os vetores mais próximos do vetor de consulta.
- Medidas de similaridade
Com base nos algoritmos discutidos anteriormente, precisamos entender o papel da medidas de similaridade em bancos de dados vetoriais. Essas medidas são a base de como um banco de dados de vetores compara e identifica os resultados mais relevantes para uma determinada consulta.
Medidas de similaridade são métodos matemáticos para determinar quão semelhantes dois vetores são em um espaço vetorial. Medidas de similaridade são usadas em bancos de dados de vetores para comparar os vetores armazenados no banco de dados e encontrar aquelas medidas que são mais semelhantes dado um determinado vetor de consulta.
Várias medidas de similaridade podem ser usadas, incluindo:
- Similaridade de cosseno: mede o cosseno do ângulo entre dois vetores em um vetor espaço. Varia de -1 a 1, onde 1 representa vetores idênticos, 0 representa vetores ortogonais aos vetores e -1 representa vetores que são diametralmente opostos.
- Distância euclidiana: mede a distância em linha reta entre dois vetores em um vetor espaço. Ele varia de 0 ao infinito, onde 0 representa vetores idênticos e valores maiores que 0 representam vetores cada vez mais dissimilares (não similares).
- Produto escalar: mede o produto das magnitudes de dois vetores e o cosseno do ângulo entre eles. Ele varia de -∞ a ∞, onde um valor positivo representa vetores que apontam na mesma direção, 0 representa vetores ortogonais e um valor negativo representa vetores que apontam em direções opostas.
A escolha da medida de similaridade afetará os resultados obtidos de um vetor na base de dados. Também é importante observar que cada medida de similaridade tem suas próprias vantagens e desvantagens, e é importante escolher o caminho certo, dependendo do caso de uso e requisitos.
- Filtros
Cada vetor armazenado no banco de dados também inclui metadados. Além da capacidade de consultar vetores semelhantes, os bancos de dados de vetores também podem filtrar os resultados com base em uma consulta de metadados. Para fazer isso, o banco de dados vetorial geralmente mantém dois índices: um índice vetorial e um índice de metadados. O banco pode efetuar a filtragem de metadados antes ou depois da própria pesquisa de vetores, mas em ambos os casos, existem dificuldades que tornam o processo de consulta mais lento.

O processo de filtragem pode ser executado antes ou depois da própria pesquisa de vetores, mas cada abordagem tem seus próprios desafios que podem afetar o desempenho da consulta:
- Pré-filtragem: Nesta abordagem, a filtragem de metadados é feita antes da busca do vetor. Isso pode ajudar a reduzir o espaço de pesquisa, mas também pode fazer com que o sistema ignore resultados que não correspondem aos critérios do filtro de metadados. Além disso, quando se tem extensos metadados a filtragem pode retardar o processo de consulta devido à sobrecarga computacional adicionada.
- Pós-filtragem: Nesta abordagem, a filtragem dos metadados é feita após a busca do vetor. Esse método pode ajudar a garantir que todos os resultados relevantes sejam considerados, mas também pode introduzir sobrecarga e deixar mais lento o processo de consulta uma vez que resultados irrelevantes precisam ser filtrados após a conclusão da pesquisa dos vetores.
Para otimizar o processo de filtragem, os bancos de dados vetoriais usam várias técnicas, como alavancar métodos de indexação avançados para metadados ou usando processamento paralelo para acelerar a tarefa de filtragem. Equilibrar as compensações entre desempenho de pesquisa e precisão de filtragem é essencial para fornecer resultados de consulta eficientes e relevantes em bancos de dados vetoriais.
Hoje em dia existem vários bancos de dados vetorias no mercado com uma ou muitas das caracteristicas listadas acima. Hoje os mais conhecidos e utilizados são:
- Milvus: é um sistema de banco de dados vetorial projetado para lidar com grandes quantidades de dados complexos de forma eficaz e eficiente. Este banco de dados vetorial oferece alta velocidade, desempenho, escalabilidade e funcionalidade e é próprio para pesquisa de similaridade, detecção de anomalias e processamento de linguagem natural.
- Weaviate: é um poderoso banco de dados que armazena e procura com eficiência vetores de alta dimensão.
- Pinecone: é um banco de dados robusto extremamente veloz e escalável. Possue suporte para dados complexos e pode melhorar as recomendações personalizadas com base nas preferências do usuário.
- Redis: é um banco com foco em dados vetoriais e com recursos de processamento eficientes para aplicações que exigem escalabilidade e manuseio de dados.
- SingleStore: pode ser uma excelente escolha para processamento de dados escalável e e utilização em analytics que exigem alto desempenho.
- Relevance AI: mais recomendado para armazenar, pesquisar e analisar facilmente grandes quantidades de dados.
- Qdrant: é uma solução de banco de dados versátil que oferece gerenciamento e análise de dados eficazes. Ele se destaca no uso de busca de similaridades, recomendações, detecção de anomalias e pesquisa em imagens e textos.
- Vespa: se destaca em fornecer sugestões personalizadas combinando aprendizado de máquina com informações em tempo real. É a escolha ideal para mídia e aplicativos orientados a conteúdo.
Referencias:
- https://www.pinecone.io/
- Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xi[1]angyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, et al. 2021. Milvus: A Purpose-Built Vector Data Management System. In Proceedings of the 2021 International Conference on Management of Data. 2614–2627.
- Amrita Pathak. 8 Best Vector Databases to Unleash the True Potential of AI. < https://geekflare.com/best-vector-databases/> . June 2, 2023.
- Frank Liu. A Gentle Introduction to Vector Databases. https://frankzliu.com/blog/a-gentle-introduction-to-vector-databases. Dec 23, 2021.
- Adrian Bridgwater. The Rise Of Vector Databases. < https://www.forbes.com/sites/ adrianbridgwater/2023/05/19/the-rise-of-vector-databases/?sh=34d2f2a414a6>. May 19, 2023.











