
Uma das principais dúvidas na qual se deparam as organizações é qual técnologia (Relacional ou NoSQL) utilizar para armazenar dados para Big Data. Uma forma de se resolver esta questão é primeiro determinar o tipo de análise que será feito sobre estes dados. Mas antes de entrarmos neste assunto vamos repassar primeiramente as características de cada tipo de armazenamento de dados.
Em banco de dados relacional a arquitetura mais difundida na literatura é a Arquitetura “Three-Schema” (também conhecida como arquitetura ANSI/SPARC), proposta por Tsichritzis & Klug em 1978.
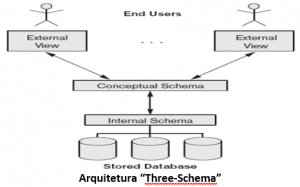
A meta desta arquitetura, é separar as aplicações de usuários da base de dados física. Nesta arquitetura, esquemas podem ser definidos em três níveis:
- O nível interno tem um esquema que descreve a estrutura de armazenamento físico da base de dados. O esquema interno usa um modelo de dados físico e descreve todos os detalhes de armazenamento de dados e caminhos de acesso à base de dados;
- O nível conceitual tem um esquema que descreve a estrutura de toda a base de dados. O esquema conceitual é uma descrição global da base de dados, que omite detalhes da estrutura de armazenamento físico e se concentra na descrição de entidades, tipos de dados, relacionamentos e restrições. Um modelo de dados de alto-nível ou um modelo de dados de implementação podem ser utilizados neste nível;
- O nível externo ou visão possui esquemas externos ou visões de usuários. Cada esquema externo descreve a visão da base de dados de um grupo de usuários da base de dados. Cada visão descreve, tipicamente, a parte da base de dados que um particular grupo de usuários está interessado e esconde deste o restante da base de dados. Um modelo de dados de alto-nível ou um modelo de dados de implementação podem ser usados neste nível.
A arquitetura “three-schema” pode ser utilizada para explicar conceitos de independência de dados, que podem ser definidos como a capacidade de alterar o esquema de um nível sem ter que alterar o esquema no próximo nível superior. Dois tipos de independência de dados podem ser definidos:
- Independência lógica de dados: É a capacidade de alterar o esquema conceitual sem ter que mudar os esquemas externos ou programas de aplicação. Pode-se mudar o esquema conceitual para expandir a base de dados, com a adição de novos tipos de registros (ou itens de dados), ou reduzir a base de dados removendo um tipo de registro. Neste último caso, esquemas externos que se referem apenas aos dados remanescentes não devem ser afetados.
- Independência física de dados: é a capacidade de alterar o esquema conceitual externo. Mudanças no esquema interno podem ser necessárias devido a alguma reorganização de arquivos físicos para melhorar o desempenho nas recuperações e/ou modificações. Após a reorganização, se nenhum dado foi adicionado ou perdido, não haverá necessidade de modificar o esquema conceitual.
Quando tratamos do problema de armazenamento de dados para Big Data devemos levar em consideração as seguintes características:
- Em primeiro lugar, o tamanho das coleções de dados que vão coleções de dados pequenas (de alguns teras por exemplo) e que podem ser armazenados em um disco isolado;
- O segundo aspecto é o conteúdo das coleções, que tendem a variar de texto, BLOBS e conteúdo estruturado e semi-estruturado;
- Em seguida, o terceiro aspecto é o suporte à persistência, à medida que as coleções crescem, suportes de armazenamento mais sofisticados são necessários com o desafio de decidir como organizar todos esses dados em um conjunto independente de discos (RAID) ou suportar o armazenamento dos mesmos em nuvem;
- Por fim, no que se refere ao acesso a dados, pequenas coleções requerem técnicas de acesso a dados diferentes das grandes coleções de dados que estão distribuídas em diferentes meios de armazenamento. Isso tem mudado e dependendo do uso de dados este acesso pode variar para uma solução de NFS até um DBMS com suas respectivas garantias de entrega de resultados.
Hoje estamos na era que integra esses aspectos e os Sistemas de Informação devem ser construídos considerando que eles irão acessar coleções heterogêneas de dados; Onde a heterogeneidade significa:
- Formato dos dados
- Tamanho das coleções de dados
- Suporte ao armazenamento dos dados
- Mecanismos de entrega destes dados
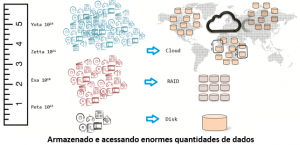
Diante desta perspectiva, o panorama atual dos sistemas de banco de dados para lidar com grandes quantidades de dados são:
- O tamanho das coleções irá interessar a partir de petas de yotas de dados multimídia e multimídia que não podem ser armazenados em um disco ou RAID de discos, mas em uma nuvem de persistência altamente distribuído,
- Tais coleções podem ser melhor modeladas de acordo com suas características e não apenas pelo modelo relacional, mas por outros modelos como gráficos, tuplas de valor-chave, colunas multidimensionais etc
- Que têm diferentes níveis de concorrência, consistência e atomicidade que determinam como eles devem ser armazenados e as condições em que operações de leitura / gravação pode ser feito. Por exemplo, a disponibilidade provavelmente levará à duplicação de dados que afetará a maneira como a consistência será assegurada. A eficiência dependerá da estratégia adotada.
Não há uma definição padrão do que vem a ser o termo NoSQL. O termo surgiu pela primeira vez com um workshop organizado em 2009, mas não há muitos argumentos sobre quais databases podem ser chamados realmente de NoSQL.
Mas enquanto não há uma definição formal, há algumas características que distinguem um banco de dados não relacional. São elas:
- Eles não usam um modelo relacional e por conseguinte não usam uma linguagem SQL
- Eles se adequam mais a rodarem em uma arquitetura de cluster
- Tendem a ser Open Source
- Eles não tem um esquema fixo, permitindo assim armazenar qualquer tipo de dado em qualquer registro
De acordo com a organização NoSQL DB (http://nosql-database.org), a forma como NoSQL armazena os dados será a próxima geração de bancos de dados: não-relacionais, distribuídos, horizontalmente escaláveis e com alta performance.
Existem hoje quatro tipos de bancos de dados NoSQL existentes. São eles:
Key-value: Sistemas que armazenam valores e um índice para encontrá-los e que é baseado em um ID (key).
Quando usar
- Desde que o acesso ao banco de dados é apenas através de uma chave primária, geralmente o desempenho é grande e o dimensionamento é fácil via sharding.
- Armazenamento de informações por sessão (cache e distribuído)
- Perfis de usuário / preferências
- Dados do carrinho de compras (cluster distribuído)
Quando não usar
- Uma vez que você só pode consultar pela chave primária, isso significa que você não pode ver a estrutura dentro de uma agregação.
- Quando houver relacionamentos entre os dados
- Transações multi-task
- Consulta por dados
- Operações por conjuntos
Documento: Sistemas que armazenam documentos providenciando índices e mecanismos simples de queries.
Quando usar
- Registro de eventos
- Sistemas de gerenciamento de conteúdo, plataformas de blogs
- Web Analytics ou Analytics em Tempo Real
- Aplicações de comércio eletrônico
Quando não usar
- Transações complexas abrangendo diferentes operações
- Consultas estrutura de diferentes agregações
Colunar: Sistemas que armazenam extensões de registros e que podem ser particionados verticalmente e horizontalmente através de nós.
Quando usar
- Registro de eventos
- Sistemas de gerenciamento de conteúdo, plataformas de blogs
- Contadores
- Tempo de uso (expiração)
Quando não usar
- Sistemas que exigem transações ACID para leitura e gravação
- Primeiros protótipos ou picos de tecnologia iniciais, o custo de uma alteração de consulta pode ser maior em comparação com uma alteração de esquema (problema que o Netflix teve quando iniciou)
Grafos: Sistemas que armazenam modelos de dados como grafos onde nós podem representar conteúdo modelado como document ou key-value estruturado e arcos que representam a relação entre o dado modelado pelo nó.
Quando usar
- Dados conectados
- Serviços de Roteamento, Despacho e Localização
- Motores de Recomendação
Quando não usar
- Quando você deseja atualizar todo o conjunto ou um subconjunto de entidades
Voltando a dúvida apresentada no começo deste artigo, em primeiro lugar precisamos avaliar o tipo de estrutura dos dados a ser analisado. Estes dados podem ser classificados como estruturados e não-estruturados.
Se os dados a serem analisados possuírem relações de dependência e interdependência de variáveis, fazer previsões, detectar defasagens e assim por diante, devemos optar por um banco de dados relacional.
Se procuramos por exemplo realizar um estudo exploratório (frequência, médias, etc) passagens por nós, ou os dados se assemelharem a redes neurais, ou ainda necessitarem de processamento de dados em paralelo o mais indicado é utilizar um banco de dados não relacional.
Existem casos onde pode ser bastante útil lançar mão de banco de dados relacional para avaliar a estrutura de relações entre as variáveis, e de posse da seleção destas variáveis, realizar a identificação individual através de modelos baseados em banco de dados NoSQL, utilizando assim o maior poder de cada tipo de banco de dados.
Referencias:
- TEOREY, T.; LIGHSTONE, S. Projeto e modelagem de banco de dados. Rio de Janeiro: Campus, 2013.
- FOWLER, M. NoSQL essencial: um guia conciso para o mundo. São Paulo: Novatec, 2013.
- RAMAKRISHNAN Raghu; Gehrke, Johannes; Sistemas de Gerenciamento de Bancos de Dados. Tradução por: Célia Taniwake; João Eduardo Nóbrega Tortello. 3.ed. São Paulo, McGraw-Hill Interamericana do Brasil Ltda, 2008.
- BREWER, E. A. Towards robust distributed systems. (Invited Talk). Principles of Distributed Computing (PODC), Portland, Oregon, Julho 2000.
- BROWNE Julian. Brewer’s CAP Theorem, 2009.












1 comentário
Conteúdo muito detalhado e esclarecedor.