
Qual a Origem da Deep Web?
Para falar sobre Deep Web é preciso descrever brevemente a sua origem e conceito. Em 1980, Tim Berners-Lee, ainda como funcionário da CERN, começou a desenvolver uma forma de conectar os documentos produzidos em cada laboratório a partir da infraestrutura de rede já existente, assim todos em qualquer laboratório poderiam ter fácil acesso aos documentos produzidos. Esta iniciativa deu origem a uma das maiores invenções da humanidade a WWW (World Wide Web). Já em 1994 o primeiro navegador havia sido lançado, o Netscape, que aliado à invenção de Tim, dava origem aos primórdios da internet como a conhecemos. Posteriormente, em 2000, Michael K Bergman propagou que o browser(navegador) serviria para “surfar” na rede e as diversas páginas seriam um oceano. Bergman então publicou o artigo The Deep Web: Surfacing Hidden Value. Este artigo foi a origem da expressão Deep Web ou a primeira vez em que ela apareceu publicamente, onde ele comenta:
“Embora muita coisa possa ser alcançada na rede, existe uma riqueza de informações que estão nas profundezas, portanto, perdidas.”
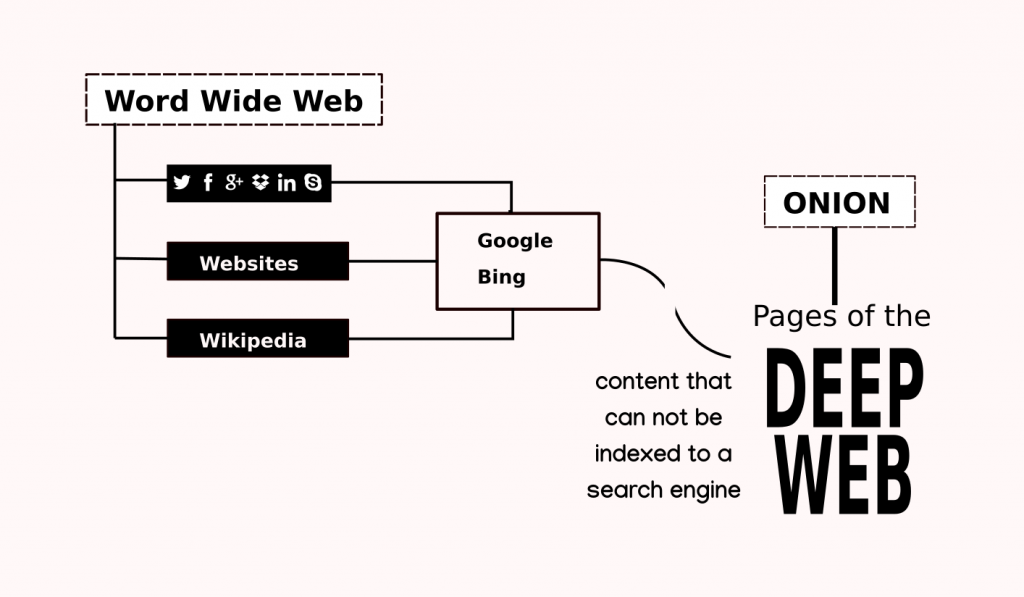
O que é a Deep Web?
Tudo que conseguimos pesquisar e acessar via buscadores tradicionais é somente o que é indexado, ou seja, as páginas indexadas pelos motores de busca da web alimentados por web crawlers ou aranhas que são robôs (programas) que varrem a internet indexando links e informações para viabilização de buscas e ranqueamento de sites. Esta parte visível já indexada é chamada de SURFACE WEB e todo o resto que está fora do alcance destes programas varredores de links e informações é chamado de DEEP WEB. Não confunda com páginas ocultadas intencionalmente, pois, em alguns governos totalitários, informações públicas na web podem ser ocultadas intencionalmente desindexando links para certas localidades específicas.

Ilustração de Web Crawlers, também conhecidos como Spiders ou Bots indexadores de sites
Alguns pesquisadores dizem que a Deep Web é tecnicamente imensurável devido ao vasto ciberespaço fora dos radares de busca das grandes empresas como a Google e por isso detém a maior parte da rede mundial. A Deep Web vai de redes descentralizadas com níveis fortes de criptografia e permissões de acesso visando o anonimato, onde os mitos sombrios moram, à Intranets de empresas privadas e dados de sistemas específicos como os da Receita Federal por exemplo. Tais exemplos podem ser classificados como parte da Deep Web pois estão fora dos mecanismos de buscas tradicionais da web e requerem softwares ou níveis específicos de permissão para acesso.
O Debate sobre o que de fato é a Deep Web não é de hoje e diversas questões são colocadas em pauta. Será realmente que a Deep Web é tudo que não se pode encontrar em buscas na web? Então seus e-mails pessoais estariam na Deep Web? Ou a Deep Web é apenas tudo que existe nas redes fechadas como a I2P, TOR, Freenet, Alienet, Demonsaw, GlobalLeaks, Infinit, Maelstron, Morphis, Hiperboria, entre outras? Muitos ainda utilizam a Deep Web e a “Dark Web” ou “Darnet” e seus mercados de drogas ilíticas e armas online, fóruns de ódio, terror, pedofilia, comércio de malwares, assassinos de aluguel, etc, como sinônimos.
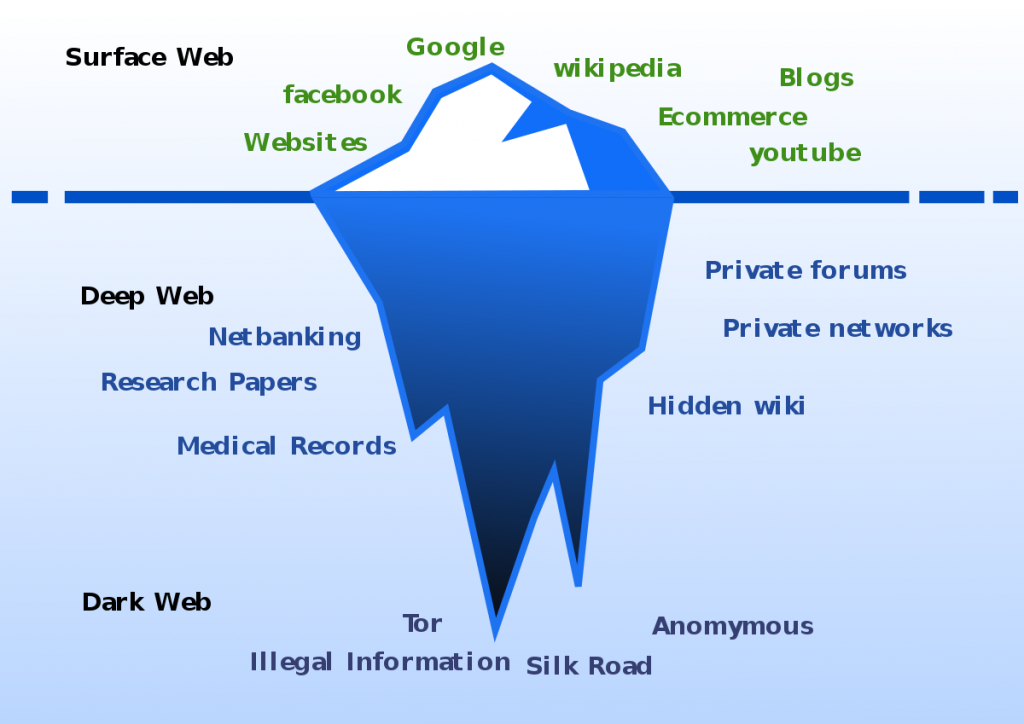
Em 2001, os especialistas em informação Chris Sherman e Gary Price lançaram o livro “The Invisible Web” iniciando uma discussão sobre a forma como a rede se apresentava na época chegando ao seguinte paradoxo sobre a web invisível (deep web):
“Ao mesmo tempo em que é fácil entender por que ela existe, não é nada simples definir ou descrevê-la concretamente, em termos específicos”.
Passa-se então a entender a Deep Web como tudo aquilo em que demanda um certo “esforço” ou algo a mais para se encontrar, fora dos radares da web comum, seja devido a necessidade de um login e senha ou a necessidade de um programa específico como o navegador TOR para o acesso.
Qual a razão de páginas estarem fora do radar dos buscadores?
Há basicamente dois motivos: ações deliberadas ou intencionais e limitações técnicas. No primeiro caso podemos citar a rede TOR criada intencionalmente para ser oculta aos olhos de curiosos e ficar longe da vigilância estatal, inicialmente visando a privacidade e a livre informação. Podemos citar também bancos de dados de artigos científicos ou revistas científicas em que para se ter acesso exige-se ser assinante e uma autenticação (um login e uma senha) ou qualquer outro tipo de conteúdo privado. Outros exemplos são os bloqueios dos indexadores pelos desenvolvedores de certos conteúdos a partir de ajustes em servidores como o uso do arquivo robots.txt na raiz do site indicando a sua exibição ou não aos indexadores.
Em relação à limitação técnica podemos citar as intranets de corporações em que os dados estão em databases internas inviabilizando a indexação de informações por mecanismos de buscas tradicionais fora desta intranet.. Antigamente certos tipos de arquivos também eram ignorados pelos buscadores como PDFs, arquivos Flashs, executáveis e arquivos compactados. Porém atualmente a tecnologia evoluiu e tais arquivos não só são exibidos em buscas como podem ser buscados diretamente por seu tipo digitando a palavra que deseja buscar seguida do comando filetype= pdf no google por exemplopara buscar pdfs. Levando em consideração este fato vale citar que Sherman e Price abordaram ainda a seguinte questão de que o visível ou invisível destina-se somente a um momento específico no tempo.
“O que é invisível hoje pode não ser amanhã caso os mecanismos de buscam decidam adicionar mais capacidade para indexar coisas novas”
Qual a profundidade da rede?
A Internet (rede mundial de computadores e demais dispositivos capazes de estabelecer conexão) permite a troca de informações por meio de protocolos de comunicação. em uma infraestrutura de rede em desenvolvimento contínuo desde a década de 1960. A Web, apesar de ser usada no mesmo sentido, é apenas um componente desta rede que permite o acesso à videos, imagens, páginas de conteúdos, etc, por meio de um navegador. E a Web Profunda, Escura, Invisível? É uma web diferente? Tecnicamente falando a ideia de comunicação por trás dos protocolos e a relação com os servidores de armazenamento nunca mudaram. Ou seja, qualquer estrutura simples que fuja dos indexadores, como já mencionado, pode-se desdobrar em infinitas possibilidades e por isso não é fácil definir ou medir a Deep Web.
Pode-se exemplificar se pensarmos em um endereço na internet que termine em “.com.br” ou “.com”. Estes sufixos são gerenciados pelo Domain Name System ou DNS que garante a identificação de um site, o lugar onde ele está hospedado e consequentemente o seu IP(Internet Protocol – que possibilita a localização física do endereço). A entidade por trás do DNS a nível internacional é o ICANN e no Brasil é o CGI (Comitê Gestor da Internet).
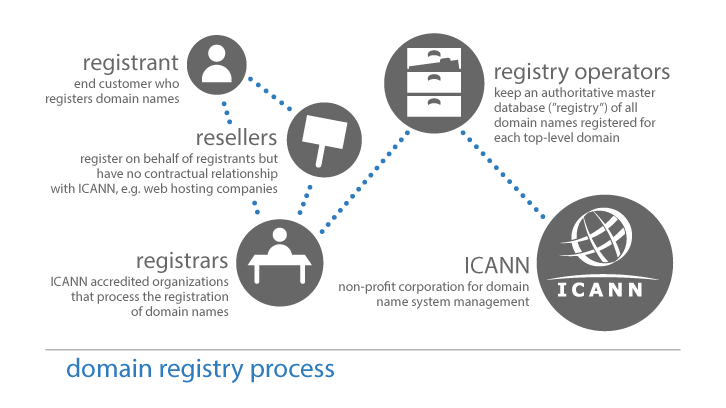
E se houvesse entidades alheias ao ICANN com suas próprias regras e que pudessem montar seus próprios domínios (DNS)? Pois elas existem e operam simultaneamente espalhando endereços variados pela Rede. A mais antiga é a namespace.us com mais de 400 opções de extensões de sites. O que essas zonas de registros alternativos têm a ver com a Deep Web? Bom a lógica de funcionamento da Web permite a criação de outras estruturas com objetivos diferentes, como uma rede em cima de outra rede. Isso ajuda a explicar o palpite de alguns estudiosos de que esse emaranhado de redes da Deep Web seja 500 vezes maior do que a Web que a Google mostra.
Mas que redes são essas?
Confira a parte 2!










