
Este artigo extraído de David Ferrucci, Anthony Levas, Sugato Bagchi, David Gondek, Erik T. Mueller apresenta uma visão para aplicar a tecnologia Watson (IBM) aos cuidados de saúde e descreve os passos necessários para adaptar e melhorar o desempenho em um novo domínio. Especificamente elaborado sobre uma visão para um sistema de apoio à decisão clínica baseada em evidências, com base na tecnologia DeepQA, que proporciona exploração de uma ampla gama de hipóteses e suas provas associadas, bem como descobrir informações ausentes que podem ser usados em misto diálogo iniciativa. Ele descreve os desafios de pesquisa, a abordagem de adaptação e relatórios finalmente os resultados das etapas.
No início em 2007, a IBM Research assumiu o grande desafio de construir um sistema de computador que pode executar bem o suficiente no domínio aberto questão de atendimento para competir com os campeões no jogo de Jeopardy! Em 2011, o sistema pergunta resposta-domínio aberto apelidado Watson era vencer os dois jogadores com classificação mais alta em um de dois jogos Jeopardy!. Mas, até que ponto pode a tecnologia QA subjacente Watson, chamado DeepQA, que foi afinado para responder perguntas, ter sucesso em um domínio radicalmente diferente e extremamente especializado, como medicamento? Este artigo descreve os passos necessários para adaptar e melhorar o desempenho neste domínio. Além disso Jeopardy permite apenas “questão em, uma resposta única para fora” sem nenhuma explicação. Os autores elaboraram uma visão para um sistema de apoio à decisão clínica baseada em evidências, com base na tecnologia DeepQA, que proporciona exploração de uma ampla gama de hipóteses e suas provas associadas, como bem como descobre informação em falta que pode ser usado na caixa de diálogo de iniciativa mista.
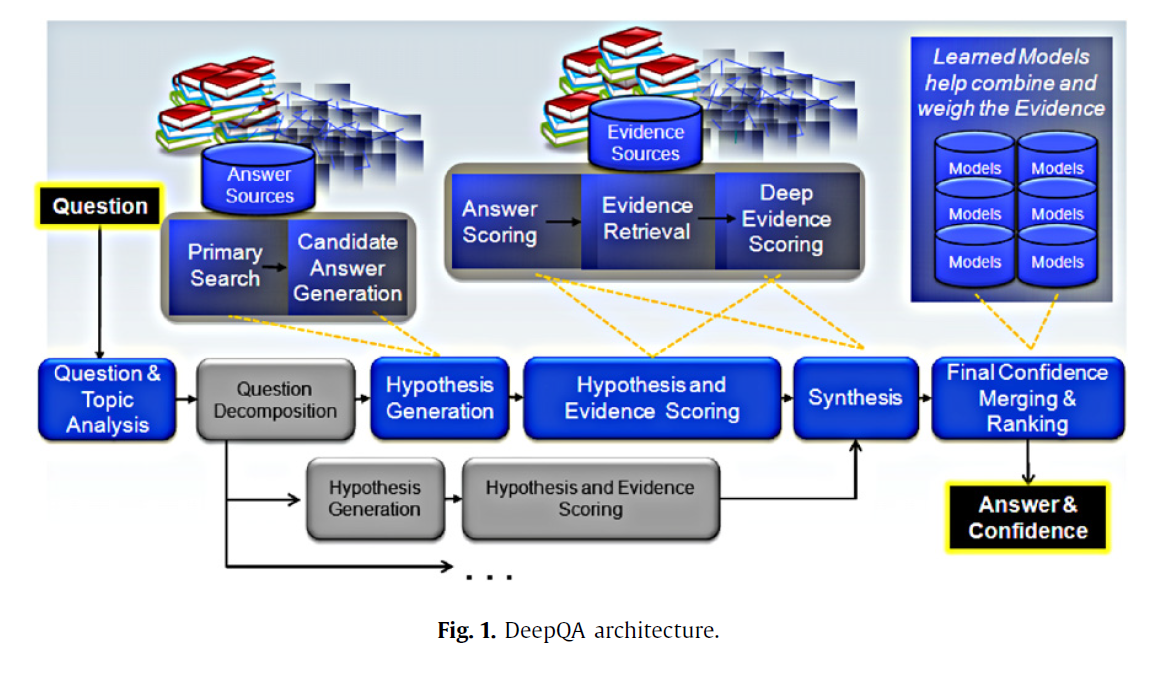
Arquitetura
DeepQA não mapeia a pergunta a um banco de dados de perguntas e simplesmente olhar para cima a resposta. DeepQA é uma arquitetura de software para análise de conteúdo de linguagem natural em ambas as questões e fontes de conhecimento. DeepQA descobre e avalia potenciais respostas e reúne e pontuações de evidências para essas respostas em ambas as fontes não estruturados, como documentos de linguagem natural e fontes estruturadas, tais como bancos de dados relacionais e bases de conhecimento. A figura acima apresenta uma visão de alto nível da arquitetura DeepQA. DeepQA tem uma arquitetura parruda massivamente paralela, baseada em componentes, que usa um conjunto extensível de fontes de conteúdo estruturados e não estruturados, bem como ampla gama de componentes de pesquisa e de pontuação conectáveis que permitem a integração de muitas técnicas analíticas diferentes de “machine-learning” que é usado para combinar pontuações de diferentes pontos. Cada resposta está ligada à sua evidência de apoio.
DeepQA é informado por uma extensa pesquisa em sistemas de responder as perguntas. Estes sistemas analisa as entradas em questão; gera e avalia respostas candidatas usando uma variedade de técnicas. DeepQA analisa uma pergunta de entrada para determinar precisamente o que está pedindo e gera muitas possíveis respostas candidatas através de uma ampla pesquisa de grandes volumes de conteúdo. Para cada uma destas respostas candidatas, a hipótese é formada com base em considerar o candidato no contexto da pergunta e tópico original. Para cada hipótese, DeepQA gera um segmento independente que tenta provar os seus resultados. DeepQA procura suas fontes de conteúdo para a evidência que ele suporta ou em caso de negação refuta esta hipótese. Para cada par hipótese de evidências, DeepQA aplica centenas de algoritmos que dissecam e analisam as evidências ao longo diferente dimensões de evidências tais como tipo de classificação, tempo, geografia, popularidade, apoio de passagem, fonte de confiabilidade, parentesco semânticos. Esta análise produz centenas de recursos. Esses recursos são então combinados com base em seu potencial aprendizado para prever a respostas corretas. O resultado final deste processo é uma lista ordenada de respostas candidatas, cada um com uma pontuação alcança confidenciando um indicativo grau em que a resposta é acreditando ser corretamente, juntamente com links para as provas.
DeepQA explora processamento de linguagem natural (NLP) e uma variedade de técnicas de pesquisa para analisar informações não estruturadas para gerar respostas candidatas e as prováveis geração de hipótese ( análogo de transmitir encadeamento). Dentro coleta de provas e pontuação ( análogo ao encadeamento para trás), DeepQA também usa PNL e procurar mais informações não estruturadas para findar as evidências para um ranking e pontuação respostas com base no conteúdo de linguagem natural. O uso direto de DeepQA de conhecimento prontamente disponível em conteúdo de linguagem natural torna mais flexível, sustentável e escalável, bem como custo mais eficiente ao considerar as vastas quantidades de informações e se manter atualizado com o conteúdo mais recente. O que esta abordagem carece de precisão artesanal utilizando regras específicas, que ganha em amplitude e flexibilidade.
Em um ambiente médico, por exemplo, a inteligência artificial pode ser utilizada para desenvolver uma ferramenta de apoio de diagnóstico que utiliza o contexto de um caso de entrada – um rico conjunto de observações sobre a condição médica de um paciente – e gera uma lista de classificação de diagnósticos ( diagnóstico diferencial) com confianças associados com base em pesquisa e análise de provas a partir de grandes volumes de conteúdo. Médicos e outros prestadores serviços na área de saúde podem avaliar esses diagnósticos em várias dimensões diferentes de evidências de que DeepQA podem extrair de prontuários eletrônicos dos pacientes e outras fontes de conteúdo relacionadas. Para a medicina, as dimensões de provas podem incluir sintomas, achados, histórico do paciente, história familiar, demografia, medicamentos atuais, e muitos outros.
Melhorar a precisão do diagnóstico e na velocidade da informação pode melhorar diretamente a qualidade dos cuidados para os pacientes, bem como reduzir o custo total incorrido neste processo por sistemas de saúde. Erros de diagnóstico relatados ao longo podem ser superados por erros médicos podem melhorar duas a quatro vezes. Elstein estima uma taxa de erro de diagnóstico de cerca de 15%, o que está de acordo com descobertas em uma série de estudos de autópsia. Singh e Graber afirmam que os “erros de diagnóstico são a maior contribuição para a negligência ambulatorial afirma (40% em alguns estudos) e custam cerca de US $ 300.000 por sinistro, em média.” Os resultados publicados a partir destas analise podemos destacar a frequência e consequência de erro de diagnóstico em sistemas de saúde hoje que podem ser reduzidos.
Uma característica fundamental de diferenciação de DeepQA é a sua força no uso de técnicas de pesquisa e PNL para processar o conhecimento presente no conteúdo de linguagem natural. Estas técnicas podem ser utilizadas para extrair informações relevantes de EMRs para fornecer o contexto para resolver casos individuais. As mesmas técnicas usadas por DeepQA podem ser adaptada para gerar diagnósticos e opções de tratamento e, em seguida, recolher evidência a partir de grandes volumes de informação para apoiar ou refutar os diagnósticos e tratamentos. A capacidade de processar efetivamente conteúdos não estruturados encontrados em recursos médicos e EMRs permite ao praticante trabalhar com o conhecimento mais atual disponível e reduzir os encargos associados com a leitura e sintetizar grandes quantidades de dados armazenados em um registro do paciente. Ele também ajuda a garantir que as provas apresentadas em apoio de um conjunto de soluções possíveis são legíveis e consumíveis por usuários humanos, porque o conteúdo é normalmente criado por outros especialistas em linguagem natural, em vez de por engenheiros do conhecimento em regras formais.
Aplicando DeepQA a qualquer novo domínio exige uma adaptação em três áreas:
- adaptação de conteúdo envolve organizar o conteúdo de domínio para hipótese e geração de evidências, a modelagem do contexto em que serão gerados perguntas – livros didáticos, dicionários, guias clínicos e artigos de pesquisa, a informação pública sobre a web.
- adaptação ao treinamento envolve a adição de dados na forma de perguntas de amostras de treinamentos e respostas corretas no domínio do alvo para que o sistema possa aprender e com os pesos adequados para seus componentes ao estimar resposta de confiança – baseia se em métodos de aprendizado de máquina para determinar como medir a contribuição dos vários componentes de pesquisa e de pontuação no pipeline das questões à serem respondidas.
- adaptação funcional envolve a adição de nova análise em questão de domínio-específicação, e a geração candidata, marcando hipótese e outros componentes – inclui analisar e interpretar uma pergunta, procurando, gerando hipóteses candidatas, recuperando evidência de apoio, e pontuação finalmente e ranquear as respostas.
Conclusão
Melhorar a precisão do diagnóstico e tratamento pode impactar diretamente a qualidade dos cuidados em pacientes, bem como reduzir o custo total incorrido pelos nossos sistemas de saúde. DeepQA define uma nova arquitetura poderosa para estruturação e raciocínio sobre o conteúdo de linguagem natural desestruturado e fornece uma base para o desenvolvimento de sistemas de apoio à decisão que pode resolver muitos dos desafios cognitivos médicos que eles enfrentam no seu dia-a-dia.

Referências
[1] Autonomy Auminence, http://www.autonomyhealth.com.
[2] G.O. Barnett, J.J. Cimino, J.A. Hupp, E.P. Hoffer, DXplain: An evolving diagnostic decision-support system, JAMA 258 (1) (1987) 67–74.
[3] E.S. Berner, Diagnostic decision support systems: Why aren’t they used more and what can we do about it?, in: AMIA Annu. Symp. Proc., 2006,pp. 1167–1168.
[4] B.G. Buchanan, E.H. Shortliffe (Eds.), Rule-Based Expert Systems: The MYCIN Experiments of the Stanford Heuristic Programming Project, Addison– Wesley, Reading, MA, 1984.
[5] D.S. Cannon, S.N. Allen, A comparison of the effects of computer and manual reminders on compliance with a mental health clinical practice guideline, J. Am. Med. Inform. Assoc. 7 (2) (2000) 196–203.
[6] W. Chapman, W. Bridewell, P. Hanbury, G. Cooper, B. Buchanan, A simple algorithm for identifying negated findings and diseases in discharge summaries, J. Biomed. Inform. 34 (5) (2001) 301–310.
[7] C. Clarke, G. Cormack, T. Lynam, Exploiting redundancy in question answering, in: Proceedings of SIGIR, 2001, pp. 358–365.
[8] E. Coiera, Guide to Health Informatics, second edition, Hodder Arnold, 2003.
[9] L. Console, L. Portinale, D.T. Dupré, Using compiled knowledge to guide and focus abductive diagnosis, IEEE Trans. Knowl. Data Eng. 8 (5) (1996) 690–706.
[10] Deep Q&A: This is Watson, IBM J. Res. Develop. 56 (3&4) (May/July 2012).
[11] S. Deerwester, S.T. Dumais, G.W. Furnas, T.K. Landauer, R. Harshman, Indexing by latent semantic analysis, J. Am. Soc. Inform. Sci. 41 (1990) 391–407.
[12] A.S. Elstein, Clinical reasoning in medicine, in: J. Higgs, M.A. Jones (Eds.), Clinical Reasoning in the Health Professions, Butterworth–Heinemann, Woburn, MA, 1995, pp. 49–59.
[13] Evaluation and Management Services Guide, Department of Health and Human Services Centers for Medicare & Medicaid Services, December 2010, ICN: 006764.
[14] Evidence-Based Medicine, http://en.wikipedia.org/wiki/Evidence-based_medicine.
[15] D. Ferrucci, E. Brown, J. Chu-Carroll, J. Fan, D. Gondek, A.A. Kalyanpur, A. Lally, J.W. Murdock, E. Nyberg, J. Prager, N. Schlaefer, C. Welty, Building Watson: An overview of the DeepQA project, AI Magazine (Fall 2010) 59–79.
[16] D. Ferrucci, A. Lally, UIMA: An architectural approach to unstructured information processing in the corporate research environment, Nat. Lang. Eng. 10 (3–4) (2004) 327–348.
[17] First CONSULT, http://www.firstconsult.com.
[18] C.P. Friedman, A.S. Elstein, F.M. Wolf, G.C. Murphy, T.M. Franz, P.S. Heckerling, P.L. Fine, T.M. Miller, V. Abraham, Enhancement of clinicians’ diagnostic reasoning by computer-based consultation: A multisite study of 2 systems, JAMA 282 (19) (1999) 1851–1856.
[19] R. Goebel, K. Furukawa, D. Poole, Using definite clauses and integrity constraints as the basis for a theory formation approach to diagnostic reasoning, in: Proceedings of the Third International Conference on Logic Programming, 1986, pp. 211–222.
[20] M. Graber, N. Franklin, R. Gordon, Diagnostic error in internal medicine, Arch. Intern. Med. 165 (2005) 1493–1499.
[21] W. Kirch, C. Schafii, Misdiagnosis at a university hospital in 4 medical eras, Medicine (Baltimore) 75 (1996) 29–40.
[22] H. Liu, A. Lussier, C. Friedman, A study of abbreviations in the UMLS, in: Proceedings of the American Medical Informatics Association Symposium, 2001, pp. 393–397.
[23] D. Moldovan, S. Harabagiu, M. Pasca, R. Mihalcea, R. Girju, R. Goodrum, V. Rus, The structure and performance of an open-domain question answering system, in: Proc. of the 38th Meeting of the Association for Computational Linguistics, 2000, pp. 563–570.
[24] J.D. Myers, The background of INTERNIST-I and QMR, in: Proceedings of ACM Conference on History of Medical Informatics, 1987, pp. 195–197.
[25] C.S. Peirce, Abduction and induction, in: J. Buchler (Ed.), Philosophical Writings of Peirce, Dover, Mineola, NY, 1901.
[26] PEPID, http://www.pepid.com/products/ddx/.
[27] H.E. Pople, On the mechanization of abductive logic, in: Proceedings of the Third International Joint Conference on Artificial Intelligence, 1972, pp. 147– 152.
[28] J. Prager, E. Brown, A. Coden, D. Radev, Question answering by predictive annotation, in: Proceedings of the ACM SIGIR Conference on Research and Development in Information Retrieval, 2000, pp. 184–191.
[29] PKC Advisor, http://www.pkc.com/software/advisor/index.aspx.
[30] P. Ramnarayan, G.C. Roberts, M. Coren, V. Nanduri, A. Tomlinson, P.M. Taylor, J.C. Wyatt, J.F. Britto, Assessment of the potential impact of a reminder system on the reduction of diagnostic errors: A quasi-experimental study, BMC Med. Inform. Decis. Mak. 6 (2006) 22.
[31] P. Ramnarayan, A. Tomlinson, A. Rao, M. Coren, A. Winrow, J. Britto, ISABEL: A web-based differential diagnostic aid for paediatrics: Results from na initial performance evaluation, Arch. Dis. Child. 88 (5) (2003) 408–413.
[32] G.D. Schiff, Diagnosing Diagnosis Errors: Lessons from a Multi-Institutional Collaborative Project, Advances in Patient Safety, vol. 2, 2005, pp. 255–278.
[33] K.G. Shojania, E.C. Burton, K.M. McDonald, L. Goldman, Changes in rates of autopsy detected diagnostic errors over time, JAMA 289 (2003) 2849–2856.
[34] T. Shortliffe, Medical thinking: What should we do?, in: Proceedings of Medical Thinking: What Do We Know? A Review Meeting, 2006, http://www.openclinical.org/medicalThinking2006Summary2.html.
[35] I. Sim, P. Gorman, R.A. Greenes, R.B. Haynes, B. Kaplan, H. Lehmann, P.C. Tang, Clinical decision support systems for the practice of evidence-based medicine, J. Am. Med. Inform. Assoc. 8 (6) (2001) 527–534.
[36] H. Singh, M. Graber, Reducing diagnostic error through medical home based primary care reform, JAMA 304 (4) (2010) 463–464, http://dx.doi.org/10.1001/jama.2010.1035.
[37] UMLS, http://www.ncbi.nlm.nih.gov/books/NBK9676/, version 2011AA.
[38] UMLS MetaMap, http://www.nlm.nih.gov/research/umls/implementation_resources/metamap.html, MetaMap version 2010.
[39] C. Wang, J. Fan, A. Kalyanpur, D. Gondek, Relation extraction with relation topics, in: Conf. on Emp. Methods in Natural Language Processing, 2011, pp. 9:1–9:12.
[40] H.R. Warner, P. Haug, O. Bouhaddou, M. Lincoln, H. Warner, D. Sorenson, J.W. Williamson, C. Fan, ILIAD as an expert consultant to teach differential diagnosis, in: Proc. Annu. Symp. Comput. Appl. Med. Care, 1988, pp. 371–376.












1 comentário
Parabéns pela matéria, me agregou muito