Uma das caracteísticas mais importantes da ciência da computação atualmente, é o estudo dos algorítmos para a compactação de dados que são trafegados através da internet para exibir filmes, mandar e-mail, enviar fotos e seja lá qual for a necessidade. Seria impossível termos as funcionalidade que temos hoje para internet, sem falar em compactação de dados. Por esse motivo, neste artigo apresentarei as bases da formação da compactação de dados.
Como este assunto é bastante complexo, vou me ater em compactação de arquivos simples, ou seja, arquivos de texto, entretanto as técnicas que vou apresentar aqui no artigo, são independente do tipo de arquivo.
Para armazenar um simples arquivo de texto em um computador, cada caractere é armazenado em um byte (8 bits). Obviamente, nem todos os 28 = 256 caracteres possíveis são usados. Pensou-se então em uma alternativa fácil para reduzir o tamanho do arquivo, que é verificar se menos de 2k caractéres são usados, usando apenas k bits neste caso, todavia essa técnica não compacta quase nada o arquivo. Pensou-se então em uma técnica mais inteligente que é considerar as frequências dos caracteres e codificar cada caractere com um número diferente de bits. Sem que esse conceito é um pouco abstrato, mas vou dar um exemplo:
Desejo compactar a palavra “cabana”. Facilmente identificamos que as frequências dos caracteres nesta palavra são f( c ) = f( b ) = f( n ) = 1/6 e f( a ) = 1/2. Temos 4 caracteres, então podemos usar 2 bits por caractere, totalizando 12 bits. Outra opção é usar os seguintes códigos: c : 000, b : 001, n : 01, a : 1. Desta forma obtemos a palavra compactada 00010011011 com 11 bits. Não parece que ganhamos muito desta forma, mas este exemplo é bem pequeno e contém pouca redundância (tente algo semelhante com a palavra “aaaaabaaaaaabaaacaaacaaaaad”). Esta compactação é chamada de compactação de Huffman e sozinha não tem muita eficiência, entretanto ela está presente como parte importante de praticamente todos os melhores compactadores usados na atualidade.
É um ponto importante como podemos decodificar a mensagem. Primeiro, precisamos saber o código de cada caractere. Precisamos também, ter uma maneira de descobrir quando acaba um caractere e começa outro. Vejamos o exemplo anterior. Começamos lendo 0. Os caracteres iniciados por 0 são “c”, “b” e “n”. Lemos então outro 0. Agora sabemos que se trata ou de um “c” ou um “b”. Ao lermos 0 novamente, temos certeza que é um “c”. Isto é possível porque geramos um código de prefixo. Um código de prefixo é uma atribuição de uma sequência distinta de bits para cada caractere de modo que uma sequência não seja um prefixo da outra. Desta forma, um código ser de prefixo é uma condição suficiente para permitir que qualquer mensagem escrita com ele possa ser decodificada de modo único, mas não é uma condição necessária para isto.
Se estamos limitados a atribuir uma sequência de um número inteiros de bits para cada caractere, sempre existe código de prefixo que usa o mínimo de bits para codificar a mensagem dentre todos os códigos, que permitiriam que qualquer mensagem escrita com ele fosse decodificada de modo único. Desta forma, não estamos perdendo nada por nos limitarmos a códigos de prefixo.
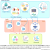
 É importante ressaltar que existe uma relação direta entre árvores binárias e códigos de prefixo. A cada folha podemos associar um caractere. Cada bit indica se devemos seguir para a direita ou esquerda na árvore.
É importante ressaltar que existe uma relação direta entre árvores binárias e códigos de prefixo. A cada folha podemos associar um caractere. Cada bit indica se devemos seguir para a direita ou esquerda na árvore.
Esta árvore exibida ao lado corresponde a palavra “cabana”. Assim, chamamos de C = {c1, …, cn} o nosso conjunto de caracteres e de f( ci ) a frequência do caractere ci. Formalmente falando, queremos construir uma árvore binária “T” que tenha como conjunto de folhas o conjunto C e que minimize:

onde l(ci) é o nível da folha ci, definido como sua distência até a raiz, ou seja, l(ci) é o número de bits usados para codificar ci. Esta árvore é chamada de árvore de Huffman de C. Espero que não tenha parecido muito difícil o conceito, pois não é. São termos apenas formais da matemática. É importante notar que as frequências dos caracteres podem ser multiplicadas livremente por qualquer constante, por isso podemos usar frequências que somem 1 ou o número de aparições de cada caractere livremente.
Esta é apenas uma abordagem ao problema de compactação de dados e existem outro muito mais complexos e com poder de compactação maior, entretanto como dito antes, quase todos utilizam árvore de Huffman nas suas bases.
Para fechar este artigo, apresento o algorítmo para um dado conjunto de caractéres C com suas frequências:
Formalmente dizemos:

Para que o descompactador decodifique um arquivo compactado com o código de Huffman ele precisa ter conhecimento da árvore. Daremos 4 alternativas para o problemas:
1) Usar uma árvore pré-estabelecida, baseada em frequências médias de cada caractere. Esta técnica sé é viável em arquivos de texto. Ainda assim, de um idioma para outro a frequência de cada caractere pode variar bastante.
2 ) Fornecer a árvore de Huffman, direta ou indiretamente, no início do arquivo. A árvore de Huffman para 256 caracteres pode ser descrita com 256 caracteres mais 511 bits usando percurso em árvore. Outra opção mais simples é informar a frequência de cada caractere e deixar que o descompactador construa a arvore. É necessário cuidado para garantir que a árvore do compactador e do descompactador sejam idênticas.
3) Fornecer a árvore de Huffman, direta ou indiretamente, para cada bloco do arquivo. Esta técnica divide o arquivo em blocos de um tamanho fixo e constrói árvores separadas para cada bloco. A vantagem é que se as frequências dos caracteres são diferentes ao longo do arquivo, pode-se obter maior compactação. A desvantagem é que várias árvores tem que ser fornecidas, gastando espaço e tempo de processamento.
4) Usar um código adaptativo. Inicia-se com uma árvore em que todo caractere tem a mesma frequência e, a cada caractere lido, incrementa-se a frequência deste caractere, atualizando a árvore. Neste caso não é necessário enviar nenhuma árvore, mas não há compactação significativa no início do arquivo.


Márcio Pulcinelli é consultor da área de Tecnologia a mais de dez anos. Os últimos oito anos foram voltados para projetos na área de gestão de sistemas em Gás & Energia e Petróleo junto aos clientes Petrobras S.A e Gas de France (GdF Suez E&P Norge AS) sendo o último, projeto no exterior (Noruega) ambos pela empresa Accenture do Brasil. Alguns anos em projetos de crédito junto ao cliente Caixa Econômica pela empresa UNISYS Outsourcing. Experiência em gestão de projetos de tecnologia, mapeamento de processos, modelagem organizacional de negócio, Implantação de Enterprise Project Management (EPM) com foco em gestão de projetos de manutenção de plataforma de petróleo e perfuração de poços exploratórios, modelagem de painéis de indicadores para CLPs (Computador Lógico Programável) em malha de gasodutos, responsável pela modelagem de sistemas de intervenções e paradas para malha de gasoduto, dentre outras áreas de atuação. Visite meu site: blog.marcio-pulcinelli.com
You must be logged in to post a comment.